 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Localization of Moments in Video Collections with Natural Language
Paper and Code


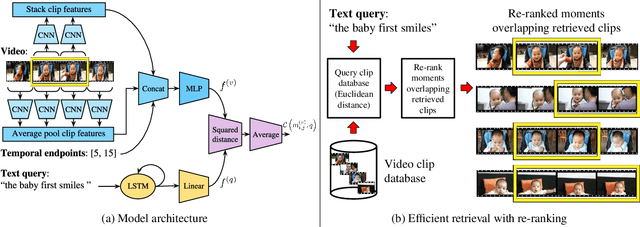
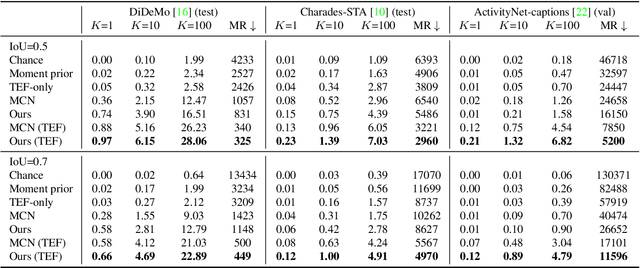
In this paper, we introduce the task of retrieving relevant video moments from a large corpus of untrimmed, unsegmented videos given a natural language query. Our task poses unique challenges as a system must efficiently identify both the relevant videos and localize the relevant moments in the videos. This task is in contrast to prior work that localizes relevant moments in a single video or searches a large collection of already-segmented videos. For our task, we introduce Clip Alignment with Language (CAL), a model that aligns features for a natural language query to a sequence of short video clips that compose a candidate moment in a video. Our approach goes beyond prior work that aggregates video features over a candidate moment by allowing for finer clip alignment. Moreover, our approach is amenable to efficient indexing of the resulting clip-level representations, which makes it suitable for moment localization in large video collections. We evaluate our approach on three recently proposed datasets for temporal localization of moments in video with natural language extended to our video corpus moment retrieval setting: DiDeMo, Charades-STA, and ActivityNet-captions. We show that our CAL model outperforms the recently proposed Moment Context Network (MCN) on all criteria across all datasets on our proposed task, obtaining an 8%-85% and 11%-47% boost for average recall and median rank, respectively, and achieves 5x faster retrieval and 8x smaller index size with a 500K video corpus.