 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-difference learning for nonlinear value function approximation in the lazy training regime
Paper and Code
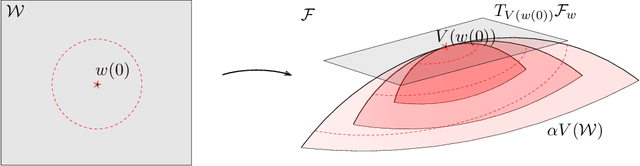


We discuss the approximation of the value function for infinite-horizon discounted Markov Decision Processes (MDP) with nonlinear functions trained with Temporal-Difference (TD) learning algorithm. We consider this problem under a certain scaling of the approximating function, leading to a regime called lazy training. In this regime the parameters of the model vary only slightly during the learning process, a feature that has recently been observed in the training of neural networks, where the scaling we study arises naturally, implicit in the initialization of their parameters. Both in the under- and over-parametrized frameworks, we prove exponential convergence to local, respectively global minimizers of the above algorithm in the lazy training regime. We then give examples of such convergence results in the case of models that diverge if trained with non-lazy TD learning, and in the case of neural networks.