 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempLe: Learning Template of Transitions for Sample Efficient Multi-task RL
Paper and Code

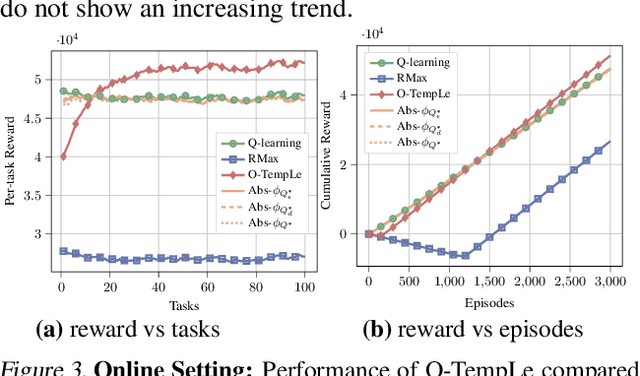
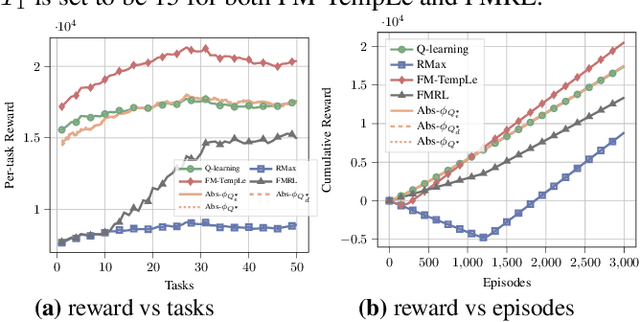
Transferring knowledge among various environments is important to efficiently learn multiple tasks online. Most existing methods directly use the previously learned models or previously learned optimal policies to learn new tasks. However, these methods may be inefficient when the underlying models or optimal policies are substantially different across tasks. In this paper, we propose Template Learning (TempLe), the first PAC-MDP method for multi-task reinforcement learning that could be applied to tasks with varying state/action space. TempLe generates transition dynamics templates, abstractions of the transition dynamics across tasks, to gain sample efficiency by extracting similarities between tasks even when their underlying models or optimal policies have limited commonalities. We present two algorithms for an "online" and a "finite-model" setting respectively. We prove that our proposed TempLe algorithms achieve much lower sample complexity than single-task learners or state-of-the-art multi-task methods. We show via systematically designed experiments that our TempLe method universally outperforms the state-of-the-art multi-task methods (PAC-MDP or not) in various settings and regimes.