 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTele-LLMs: A Series of Specialized Large Language Models for Telecommunications
Paper and Code
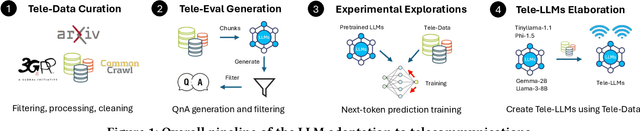
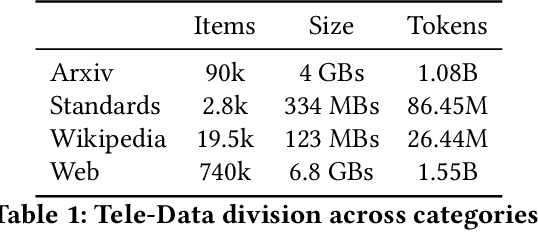
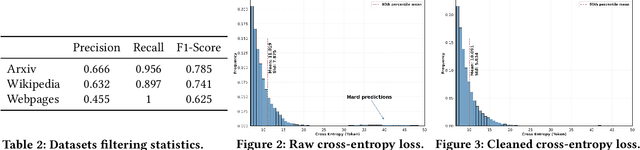
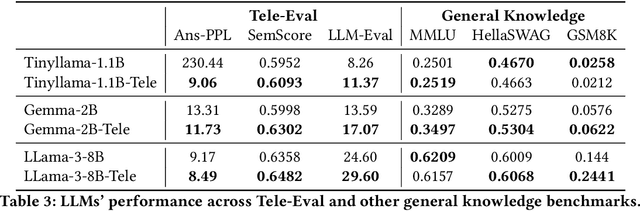
The emergence of large language models (LLMs) has significantly impacted various fields, from natural language processing to sectors like medicine and finance. However, despite their rapid proliferation, the applications of LLMs in telecommunications remain limited, often relying on general-purpose models that lack domain-specific specialization. This lack of specialization results in underperformance, particularly when dealing with telecommunications-specific technical terminology and their associated mathematical representations. This paper addresses this gap by first creating and disseminating Tele-Data, a comprehensive dataset of telecommunications material curated from relevant sources, and Tele-Eval, a large-scale question-and-answer dataset tailored to the domain. Through extensive experiments, we explore the most effective training techniques for adapting LLMs to the telecommunications domain, ranging from examining the division of expertise across various telecommunications aspects to employing parameter-efficient techniques. We also investigate how models of different sizes behave during adaptation and analyze the impact of their training data on this behavior. Leveraging these findings, we develop and open-source Tele-LLMs, the first series of language models ranging from 1B to 8B parameters, specifically tailored for telecommunications. Our evaluations demonstrate that these models outperform their general-purpose counterparts on Tele-Eval while retaining their previously acquired capabilities, thus avoiding the catastrophic forgetting phenomenon.