 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDAN: Top-Down Attention Networks for Enhanced Feature Selectivity in CNNs
Paper and Code



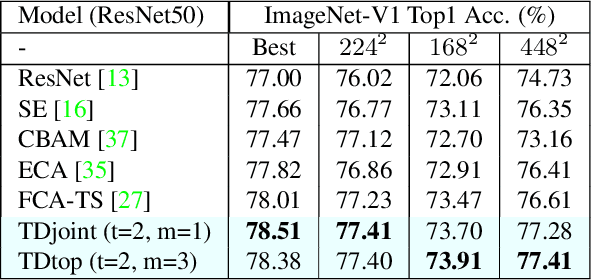
Attention modules for Convolutional Neural Networks (CNNs) are an effective method to enhance performance of networks on multiple computer-vision tasks. While many works focus on building more effective modules through appropriate modelling of channel-, spatial- and self-attention, they primarily operate in a feedfoward manner. Consequently, the attention mechanism strongly depends on the representational capacity of a single input feature activation, and can benefit from incorporation of semantically richer higher-level activations that can specify "what and where to look" through top-down information flow. Such feedback connections are also prevalent in the primate visual cortex and recognized by neuroscientists as a key component in primate visual attention. Accordingly, in this work, we propose a lightweight top-down (TD) attention module that iteratively generates a "visual searchlight" to perform top-down channel and spatial modulation of its inputs and consequently outputs more selective feature activations at each computation step. Our experiments indicate that integrating TD in CNNs enhances their performance on ImageNet-1k classification and outperforms prominent attention modules while being more parameter and memory efficient. Further, our models are more robust to changes in input resolution during inference and learn to "shift attention" by localizing individual objects or features at each computation step without any explicit supervision. This capability results in 5% improvement for ResNet50 on weakly-supervised object localization besides improvements in fine-grained and multi-label classification.