 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaylorBeamformer: Learning All-Neural Beamformer for Multi-Channel Speech Enhancement from Taylor's Approximation Theory
Paper and Code
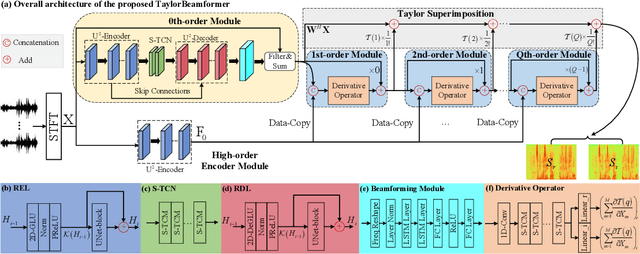
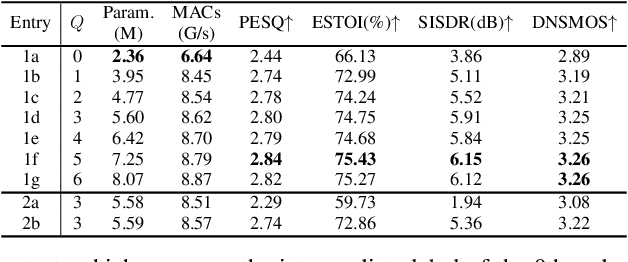
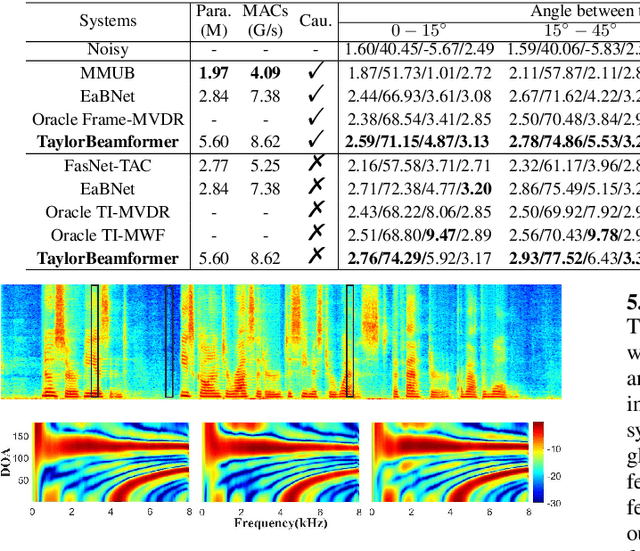
While existing end-to-end beamformers achieve impressive performance in various front-end speech processing tasks, they usually encapsulate the whole process into a black box and thus lack adequate interpretability. As an attempt to fill the blank, we propose a novel neural beamformer inspired by Taylor's approximation theory called TaylorBeamformer for multi-channel speech enhancement. The core idea is that the recovery process can be formulated as the spatial filtering in the neighborhood of the input mixture. Based on that, we decompose it into the superimposition of the 0th-order non-derivative and high-order derivative terms, where the former serves as the spatial filter and the latter is viewed as the residual noise canceller to further improve the speech quality. To enable end-to-end training, we replace the derivative operations with trainable networks and thus can learn from training data. Extensive experiments are conducted on the synthesized dataset based on LibriSpeech and results show that the proposed approach performs favorably against the previous advanced baselines.