 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting Optimal Active Learning via Example Quality
Paper and Code
Jul 30, 2014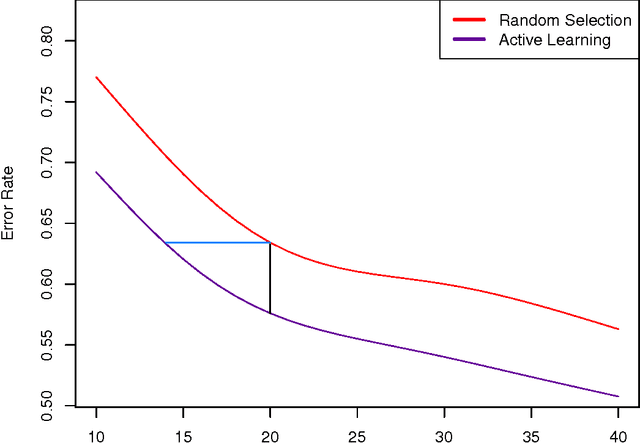
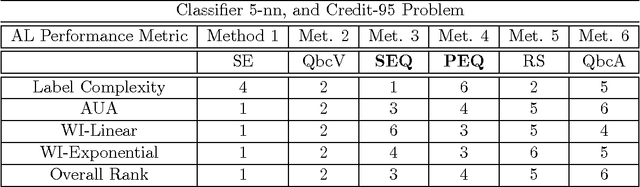
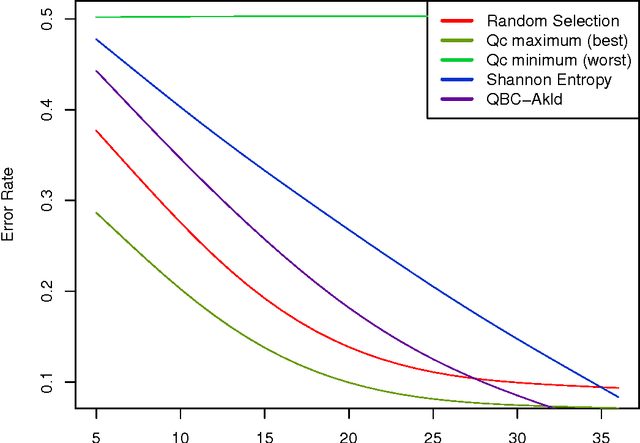
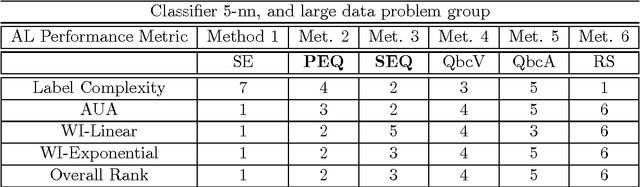
In many classification problems unlabelled data is abundant and a subset can be chosen for labelling. This defines the context of active learning (AL), where methods systematically select that subset, to improve a classifier by retraining. Given a classification problem, and a classifier trained on a small number of labelled examples, consider the selection of a single further example. This example will be labelled by the oracle and then used to retrain the classifier. This example selection raises a central question: given a fully specified stochastic description of the classification problem, which example is the optimal selection? If optimality is defined in terms of loss, this definition directly produces expected loss reduction (ELR), a central quantity whose maximum yields the optimal example selection. This work presents a new theoretical approach to AL, example quality, which defines optimal AL behaviour in terms of ELR. Once optimal AL behaviour is defined mathematically, reasoning about this abstraction provides insights into AL. In a theoretical context the optimal selection is compared to existing AL methods, showing that heuristics can make sub-optimal selections. Algorithms are constructed to estimate example quality directly. A large-scale experimental study shows these algorithms to be competitive with standard AL methods.