 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Transformed Regression for Accurate Tracking
Paper and Code


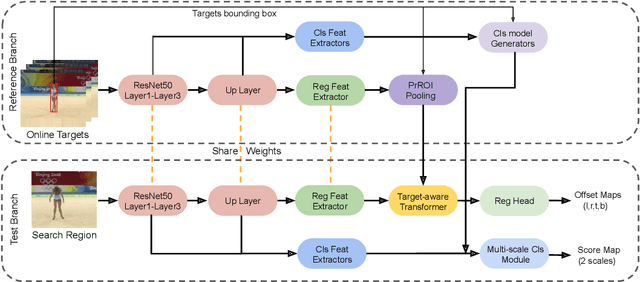
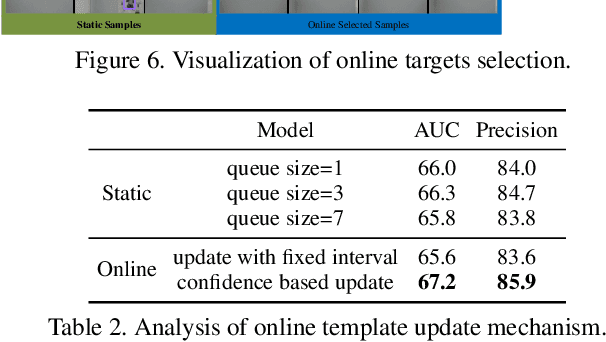
Accurate tracking is still a challenging task due to appearance variations, pose and view changes, and geometric deformations of target in videos. Recent anchor-free trackers provide an efficient regression mechanism but fail to produce precise bounding box estimation. To address these issues, this paper repurposes a Transformer-alike regression branch, termed as Target Transformed Regression (TREG), for accurate anchor-free tracking. The core to our TREG is to model pair-wise relation between elements in target template and search region, and use the resulted target enhanced visual representation for accurate bounding box regression. This target contextualized representation is able to enhance the target relevant information to help precisely locate the box boundaries, and deal with the object deformation to some extent due to its local and dense matching mechanism. In addition, we devise a simple online template update mechanism to select reliable templates, increasing the robustness for appearance variations and geometric deformations of target in time. Experimental results on visual tracking benchmarks including VOT2018, VOT2019, OTB100, GOT10k, NFS, UAV123, LaSOT and TrackingNet demonstrate that TREG obtains the state-of-the-art performance, achieving a success rate of 0.640 on LaSOT, while running at around 30 FPS. The code and models will be made available at https://github.com/MCG-NJU/TREG.