 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTArC: Incrementally and Semi-Automatically Collecting a Tunisian Arabish Corpus
Paper and Code
Mar 24, 2020
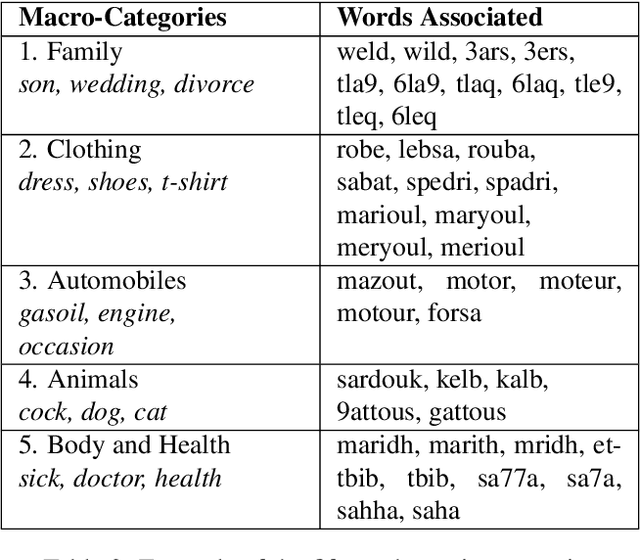
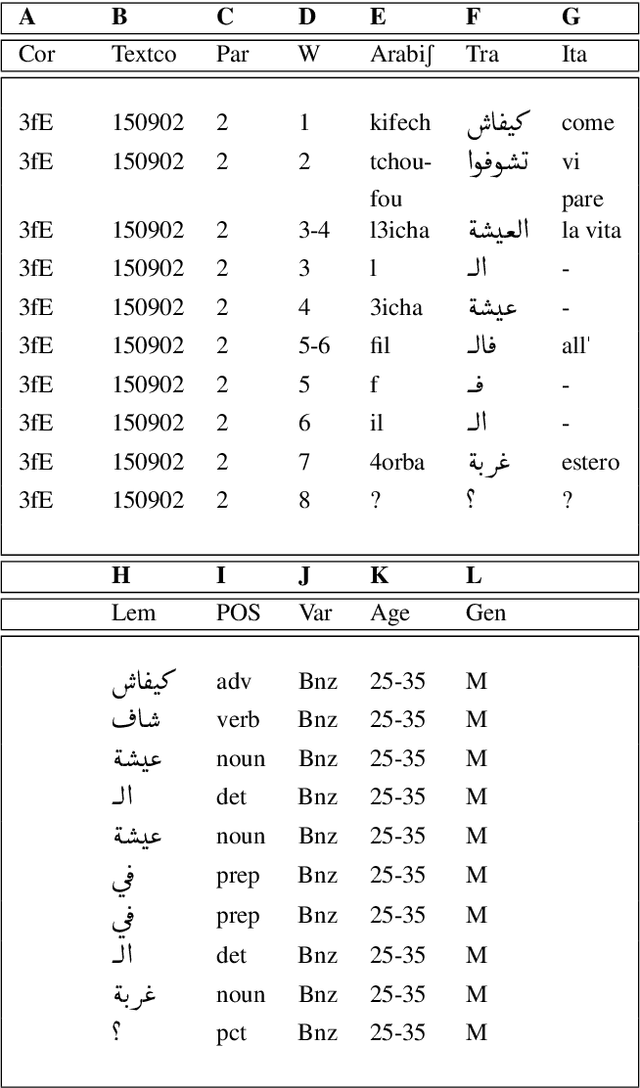

This article describes the constitution process of the first morpho-syntactically annotated Tunisian Arabish Corpus (TArC). Arabish, also known as Arabizi, is a spontaneous coding of Arabic dialects in Latin characters and arithmographs (numbers used as letters). This code-system was developed by Arabic-speaking users of social media in order to facilitate the writing in the Computer-Mediated Communication (CMC) and text messaging informal frameworks. There is variety in the realization of Arabish amongst dialects, and each Arabish code-system is under-resourced, in the same way as most of the Arabic dialects. In the last few years, the focus on Arabic dialects in the NLP field has considerably increased. Taking this into consideration, TArC will be a useful support for different types of analyses, computational and linguistic, as well as for NLP tools training. In this article we will describe preliminary work on the TArC semi-automatic construction process and some of the first analyses we developed on TArC. In addition, in order to provide a complete overview of the challenges faced during the building process, we will present the main Tunisian dialect characteristics and their encoding in Tunisian Arabish.