Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangent Space Separability in Feedforward Neural Networks
Paper and Code

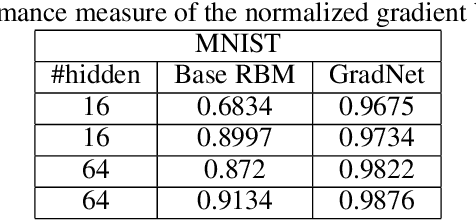
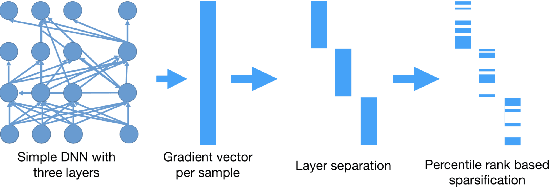
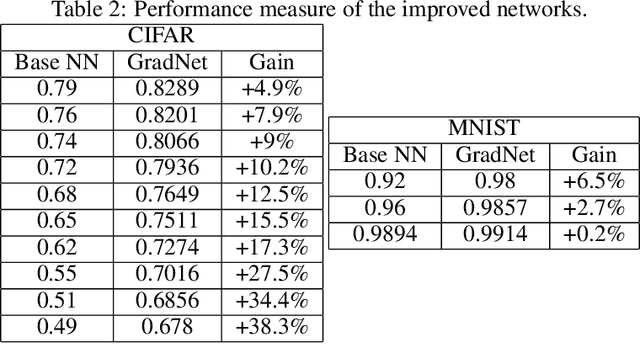
Hierarchical neural networks are exponentially more efficient than their corresponding "shallow" counterpart with the same expressive power, but involve huge number of parameters and require tedious amounts of training. By approximating the tangent subspace, we suggest a sparse representation that enables switching to shallow networks, GradNet after a very early training stage. Our experiments show that the proposed approximation of the metric improves and sometimes even surpasses the achievable performance of the original network significantly even after a few epochs of training the original feedforward network.
* 10 pages; accepted at Workshop "Beyond First-Order Optimization
Methods in Machine Learning", 33rd Conference on Neural Information
Processing Systems (NeurIPS 2019). arXiv admin note: substantial text overlap
with arXiv:1807.06630
View paper on