 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Wild Price Fluctuations: Monotone Stochastic Convex Optimization with Bandit Feedback
Paper and Code
Mar 16, 2021
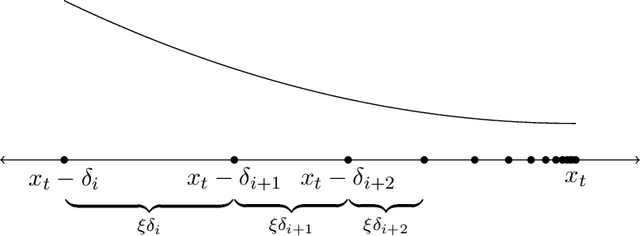
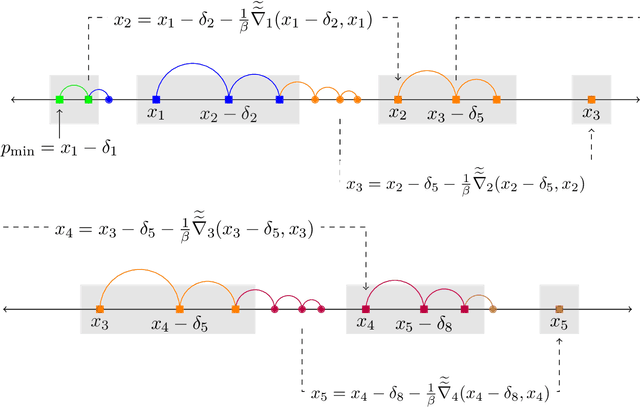
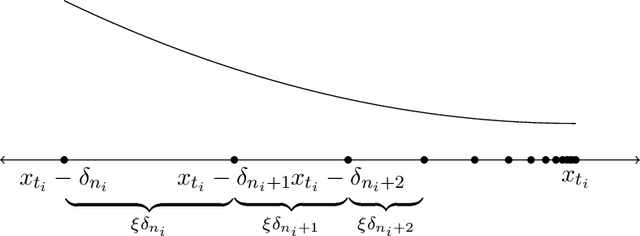
Prices generated by automated price experimentation algorithms often display wild fluctuations, leading to unfavorable customer perceptions and violations of individual fairness: e.g., the price seen by a customer can be significantly higher than what was seen by her predecessors, only to fall once again later. To address this concern, we propose demand learning under a monotonicity constraint on the sequence of prices, within the framework of stochastic convex optimization with bandit feedback. Our main contribution is the design of the first sublinear-regret algorithms for monotonic price experimentation for smooth and strongly concave revenue functions under noisy as well as noiseless bandit feedback. The monotonicity constraint presents a unique challenge: since any increase (or decrease) in the decision-levels is final, an algorithm needs to be cautious in its exploration to avoid over-shooting the optimum. At the same time, minimizing regret requires that progress be made towards the optimum at a sufficient pace. Balancing these two goals is particularly challenging under noisy feedback, where obtaining sufficiently accurate gradient estimates is expensive. Our key innovation is to utilize conservative gradient estimates to adaptively tailor the degree of caution to local gradient information, being aggressive far from the optimum and being increasingly cautious as the prices approach the optimum. Importantly, we show that our algorithms guarantee the same regret rates (up to logarithmic factors) as the best achievable rates of regret without the monotonicity requirement.