 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake More Positives: A Contrastive Learning Framework for Unsupervised Person Re-Identification
Paper and Code
Jan 12, 2021
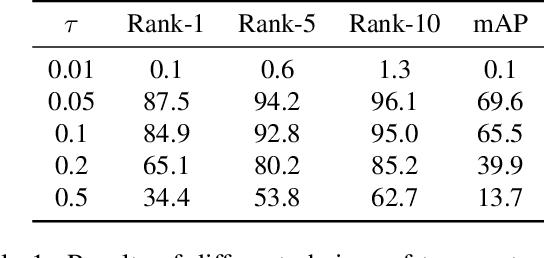


Exploring the relationship between examples without manual annotations is a core problem in the field of unsupervised person re-identification (re-ID). In the unsupervised scenario, no ground truth is provided for bringing instances of the same identity closer and spreading samples of different identities apart. In this paper, we introduce a contrastive learning framework for unsupervised person re-ID, which we call Take More Positives (TMP). In an iterative manner, TMP generates pseudo-labels by clustering samples, and updates itself with such pseudo-labels and the proposed contrastive loss. By considering more positive examples, the framework of TMP outperforms the state-of-the-art methods for unsupervised person re-ID. On the Market-1501 benchmark, TMP achieves 88.3% Rank-1 accuracy and 70.4% mean average precision. Our code will be made publicly available.