 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Early Sparse Gradients in Softmax Activation Using Leaky Squared Euclidean Distance
Paper and Code
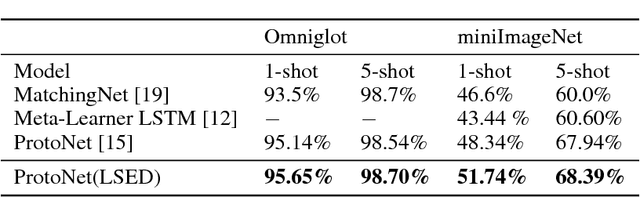
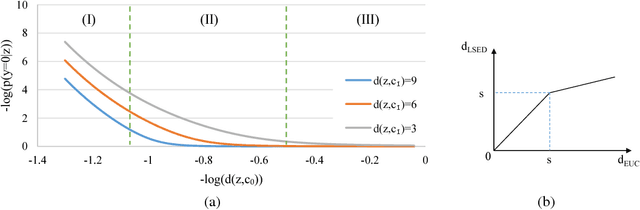

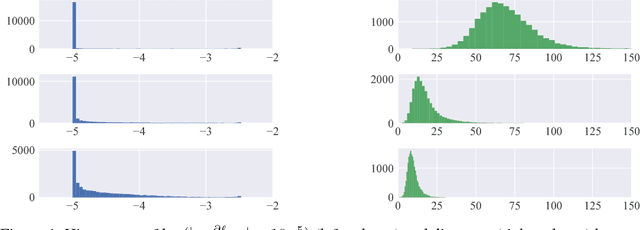
Softmax activation is commonly used to output the probability distribution over categories based on certain distance metric. In scenarios like one-shot learning, the distance metric is often chosen to be squared Euclidean distance between the query sample and the category prototype. This practice works well in most time. However, we find that choosing squared Euclidean distance may cause distance explosion leading gradients to be extremely sparse in the early stage of back propagation. We term this phenomena as the early sparse gradients problem. Though it doesn't deteriorate the convergence of the model, it may set up a barrier to further model improvement. To tackle this problem, we propose to use leaky squared Euclidean distance to impose a restriction on distances. In this way, we can avoid distance explosion and increase the magnitude of gradients. Extensive experiments are conducted on Omniglot and miniImageNet datasets. We show that using leaky squared Euclidean distance can improve one-shot classification accuracy on both datasets.