 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-vectors: Weakly Supervised Speaker Identification Using Hierarchical Transformer Model
Paper and Code
Oct 29, 2020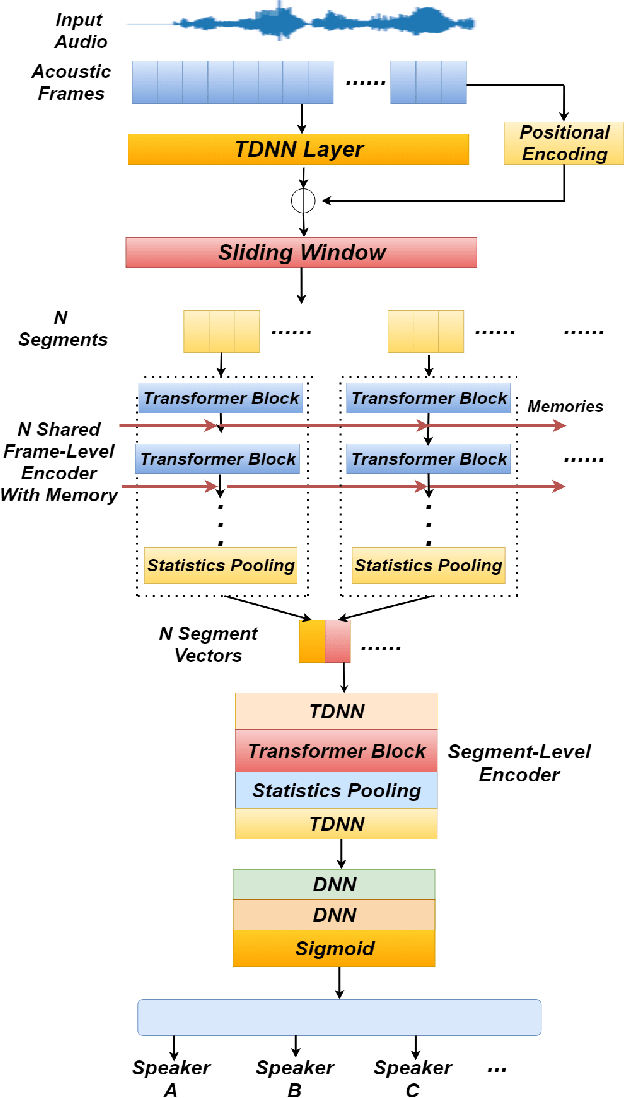
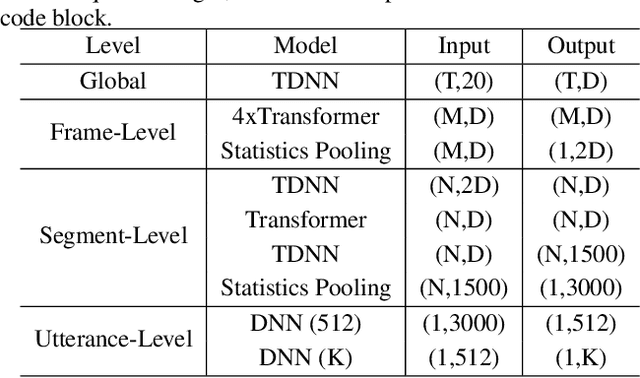
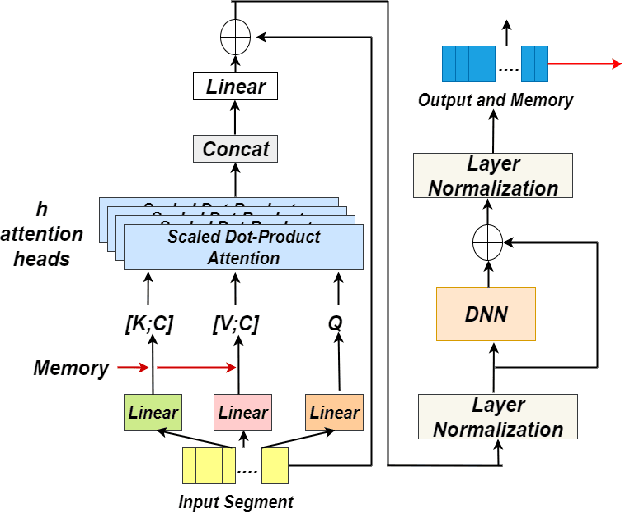
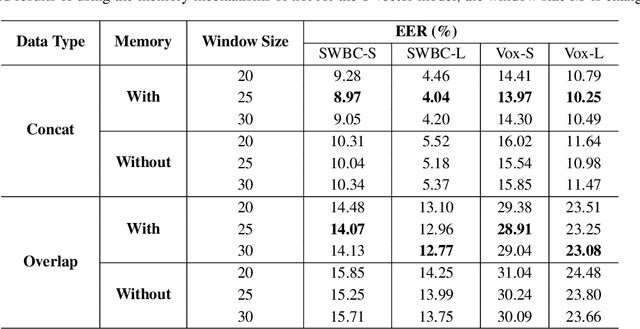
Identifying multiple speakers without knowing where a speaker's voice is in a recording is a challenging task. This paper proposes a hierarchical network with transformer encoders and memory mechanism to address this problem. The proposed model contains a frame-level encoder and segment-level encoder, both of them make use of the transformer encoder block. The multi-head attention mechanism in the transformer structure could better capture different speaker properties when the input utterance contains multiple speakers. The memory mechanism used in the frame-level encoders can build a recurrent connection that better capture long-term speaker features. The experiments are conducted on artificial datasets based on the Switchboard Cellular part1 (SWBC) and Voxceleb1 datasets. In different data construction scenarios (Concat and Overlap), the proposed model shows better performance comparaing with four strong baselines, reaching 13.3% and 10.5% relative improvement compared with H-vectors and S-vectors. The use of memory mechanism could reach 10.6% and 7.7% relative improvement compared with not using memory mechanism.