 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edget-Soft Update of Target Network for Deep Reinforcement Learning
Paper and Code
Aug 25, 2020
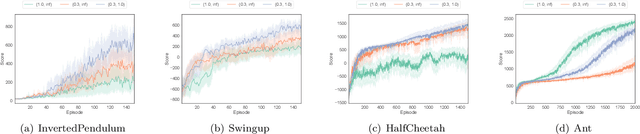

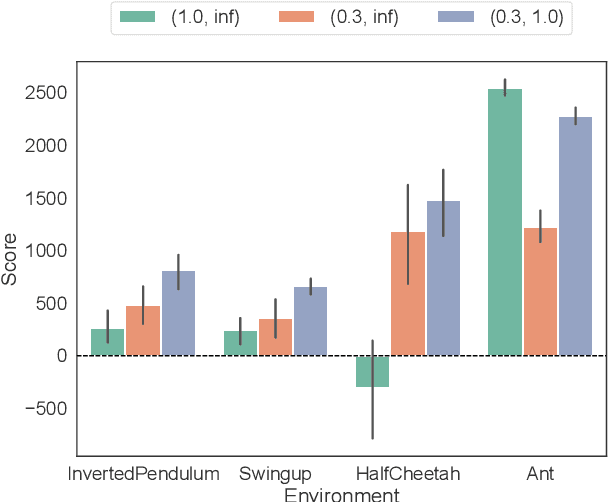
This paper proposes a new robust update rule of the target network for deep reinforcement learning, to replace the conventional update rule, given as an exponential moving average. The problem with the conventional rule is the fact that all the parameters are smoothly updated with the same speed, even when some of them are trying to update toward the wrong directions. To robustly update the parameters, the t-soft update, which is inspired by the student-t distribution, is derived with reference to the analogy between the exponential moving average and the normal distribution. In most of PyBullet robotics simulations, an online actor-critic algorithm with the t-soft update outperformed the conventional methods in terms of the obtained return.