 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Net: Encoder-Decoder in Encoder-Decoder architecture for the main vessel segmentation in coronary angiography
Paper and Code
May 10, 2019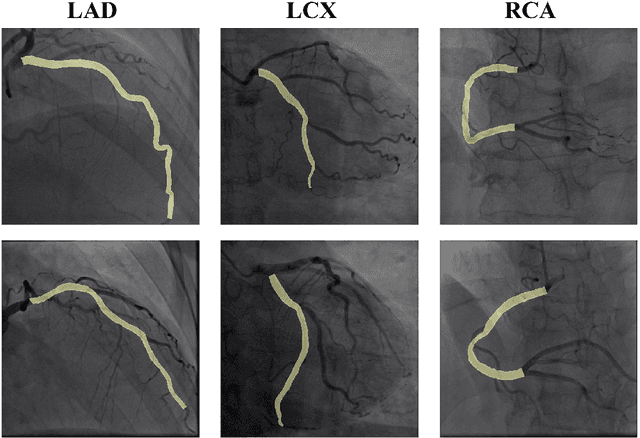
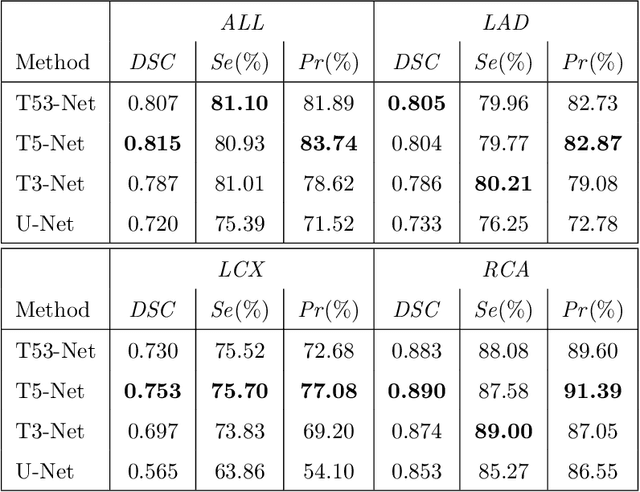
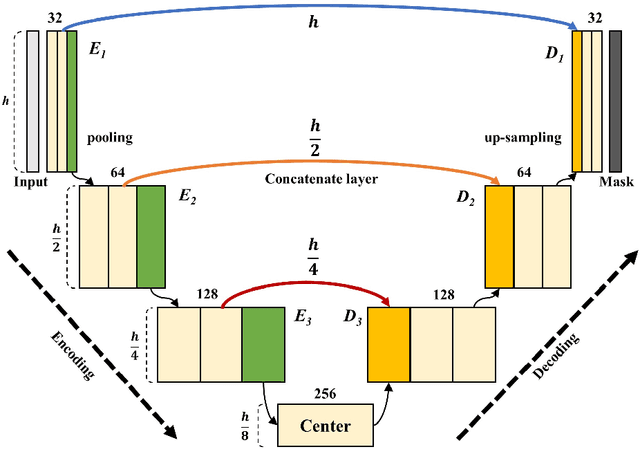
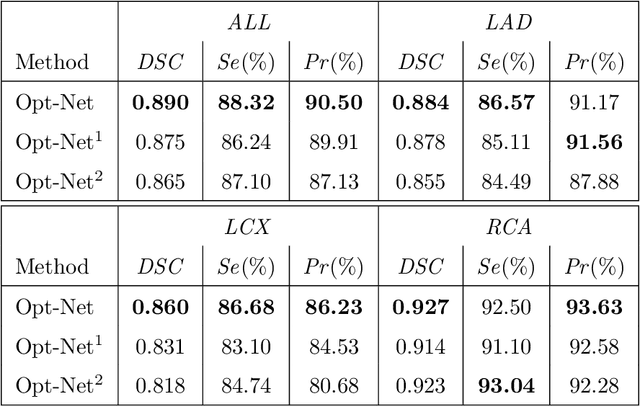
In this paper, we proposed T-Net containing a small encoder-decoder inside the encoder-decoder structure (EDiED). T-Net overcomes the limitation that U-Net can only have a single set of the concatenate layer between encoder and decoder block. To be more precise, the U-Net symmetrically forms the concatenate layers, so the low-level feature of the encoder is connected to the latter part of the decoder, and the high-level feature is connected to the beginning of the decoder. T-Net arranges the pooling and up-sampling appropriately during the encoder process, and likewise during the decoding process so that feature-maps of various sizes are obtained in a single block. As a result, all features from the low-level to the high-level extracted from the encoder are delivered from the beginning of the decoder to predict a more accurate mask. We evaluated T-Net for the problem of segmenting three main vessels in coronary angiography images. The experiment consisted of a comparison of U-Net and T-Nets under the same conditions, and an optimized T-Net for the main vessel segmentation. As a result, T-Net recorded a Dice Similarity Coefficient score (DSC) of 0.815, 0.095 higher than that of U-Net, and the optimized T-Net recorded a DSC of 0.890 which was 0.170 higher than that of U-Net. In addition, we visualized the weight activation of the convolutional layer of T-Net and U-Net to show that T-Net actually predicts the mask from earlier decoders. Therefore, we expect that T-Net can be effectively applied to other similar medical image segmentation problems.