 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYNTHESIS: A Semi-Asynchronous Path-Integrated Stochastic Gradient Method for Distributed Learning in Computing Clusters
Paper and Code
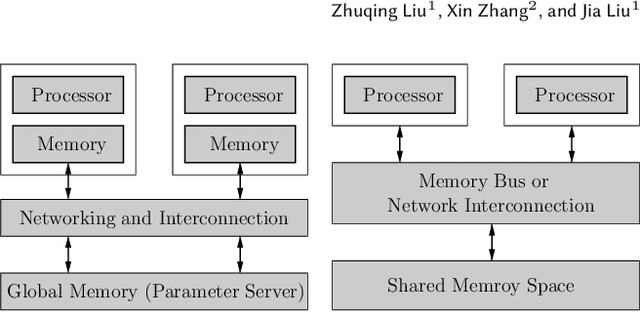


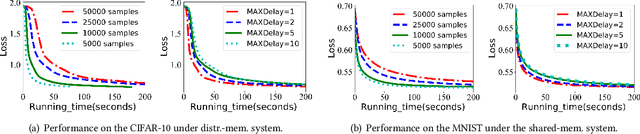
To increase the training speed of distributed learning, recent years have witnessed a significant amount of interest in developing both synchronous and asynchronous distributed stochastic variance-reduced optimization methods. However, all existing synchronous and asynchronous distributed training algorithms suffer from various limitations in either convergence speed or implementation complexity. This motivates us to propose an algorithm called STNTHESIS (semi-asynchronous path-integrated stochastic gradient search), which leverages the special structure of the variance-reduction framework to overcome the limitations of both synchronous and asynchronous distributed learning algorithms while retaining their salient features. We consider two implementations of STNTHESIS under distributed and shared memory architectures. We show that our STNTHESIS algorithms have $O(\sqrt{N}\epsilon^{-2}(\Delta+1)+N)$ and $O(\sqrt{N}\epsilon^{-2}(\Delta+1) d+N)$ computational complexities for achieving an $\epsilon$-stationary point in non-convex learning under distributed and shared memory architectures, respectively, where N denotes the total number of training samples and $\Delta$ represents the maximum delay of the workers. Moreover, we investigate the generalization performance of \algname by establishing algorithmic stability bounds for quadratic strongly convex and non-convex optimization. We further conduct extensive numerical experiments to verify our theoretical findings