 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergy and Symmetry in Deep Learning: Interactions between the Data, Model, and Inference Algorithm
Paper and Code
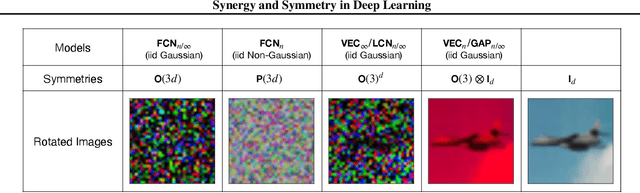


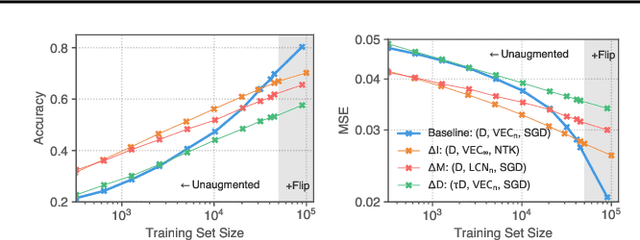
Although learning in high dimensions is commonly believed to suffer from the curse of dimensionality, modern machine learning methods often exhibit an astonishing power to tackle a wide range of challenging real-world learning problems without using abundant amounts of data. How exactly these methods break this curse remains a fundamental open question in the theory of deep learning. While previous efforts have investigated this question by studying the data (D), model (M), and inference algorithm (I) as independent modules, in this paper, we analyze the triplet (D, M, I) as an integrated system and identify important synergies that help mitigate the curse of dimensionality. We first study the basic symmetries associated with various learning algorithms (M, I), focusing on four prototypical architectures in deep learning: fully-connected networks (FCN), locally-connected networks (LCN), and convolutional networks with and without pooling (GAP/VEC). We find that learning is most efficient when these symmetries are compatible with those of the data distribution and that performance significantly deteriorates when any member of the (D, M, I) triplet is inconsistent or suboptimal.