 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinTrack: A Simple and Strong Baseline for Transformer Tracking
Paper and Code
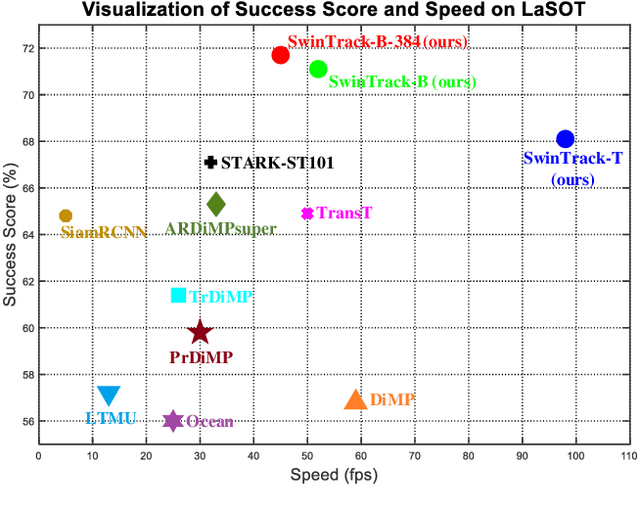
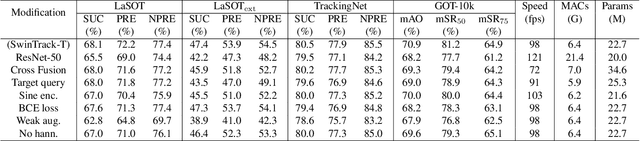
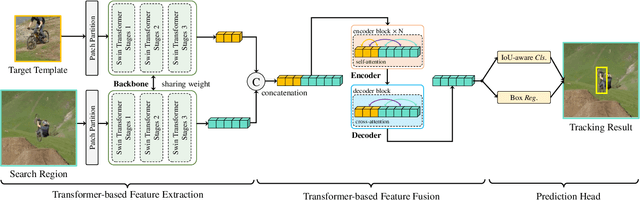
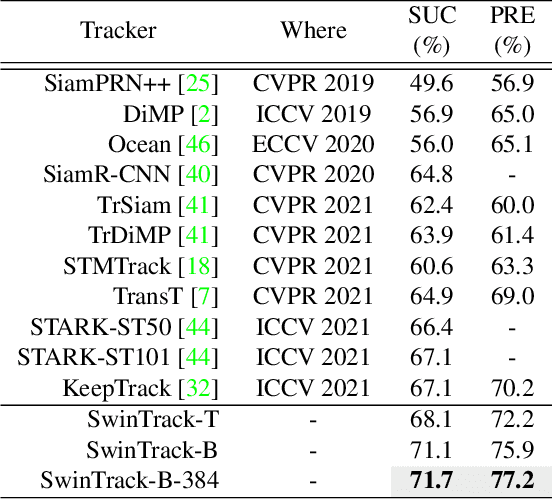
Transformer has recently demonstrated clear potential in improving visual tracking algorithms. Nevertheless, existing transformer-based trackers mostly use Transformer to fuse and enhance the features generated by convolutional neural networks (CNNs). By contrast, in this paper, we propose a fully attentional-based Transformer tracking algorithm, Swin-Transformer Tracker (SwinTrack). SwinTrack uses Transformer for both feature extraction and feature fusion, allowing full interactions between the target object and the search region for tracking. To further improve performance, we investigate comprehensively different strategies for feature fusion, position encoding, and training loss. All these efforts make SwinTrack a simple yet solid baseline. In our thorough experiments, SwinTrack sets a new record with 0.702 SUC on LaSOT, surpassing STARK by 3.1% while still running at 45 FPS. Besides, it achieves state-of-the-art performances with 0.476 SUC, 0.840 SUC and 0.694 AO on other challenging LaSOT$_{ext}$, TrackingNet, and GOT-10k datasets. Our implementation and trained models are available at https://github.com/LitingLin/SwinTrack.