 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVVAD: Personal Voice Activity Detection for Speaker Verification
Paper and Code
May 31, 2023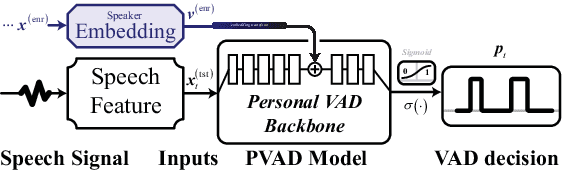



Voice activity detection (VAD) improves the performance of speaker verification (SV) by preserving speech segments and attenuating the effects of non-speech. However, this scheme is not ideal: (1) it fails in noisy environments or multi-speaker conversations; (2) it is trained based on inaccurate non-SV sensitive labels. To address this, we propose a speaker verification-based voice activity detection (SVVAD) framework that can adapt the speech features according to which are most informative for SV. To achieve this, we introduce a label-free training method with triplet-like losses that completely avoids the performance degradation of SV due to incorrect labeling. Extensive experiments show that SVVAD significantly outperforms the baseline in terms of equal error rate (EER) under conditions where other speakers are mixed at different ratios. Moreover, the decision boundaries reveal the importance of the different parts of speech, which are largely consistent with human judgments.