 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVP-CF: Selection via Proxy for Collaborative Filtering Data
Paper and Code
Jul 11, 2021

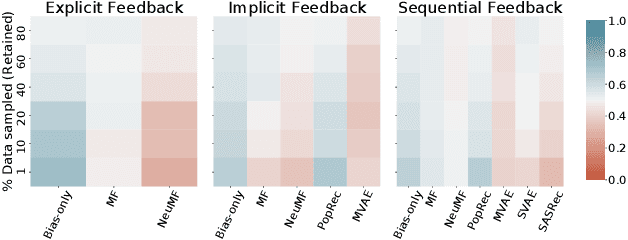

We study the practical consequences of dataset sampling strategies on the performance of recommendation algorithms. Recommender systems are generally trained and evaluated on samples of larger datasets. Samples are often taken in a naive or ad-hoc fashion: e.g. by sampling a dataset randomly or by selecting users or items with many interactions. As we demonstrate, commonly-used data sampling schemes can have significant consequences on algorithm performance -- masking performance deficiencies in algorithms or altering the relative performance of algorithms, as compared to models trained on the complete dataset. Following this observation, this paper makes the following main contributions: (1) characterizing the effect of sampling on algorithm performance, in terms of algorithm and dataset characteristics (e.g. sparsity characteristics, sequential dynamics, etc.); and (2) designing SVP-CF, which is a data-specific sampling strategy, that aims to preserve the relative performance of models after sampling, and is especially suited to long-tail interaction data. Detailed experiments show that SVP-CF is more accurate than commonly used sampling schemes in retaining the relative ranking of different recommendation algorithms.