 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURFNet: Super-resolution of Turbulent Flows with Transfer Learning using Small Datasets
Paper and Code
Aug 17, 2021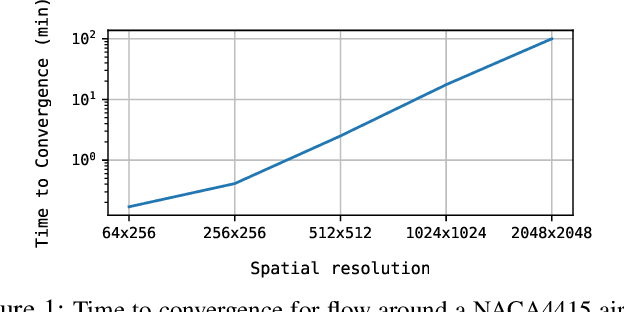
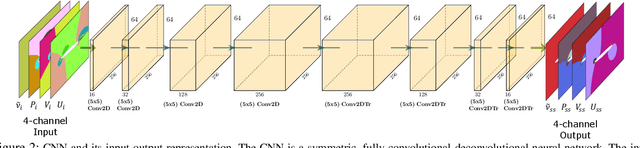
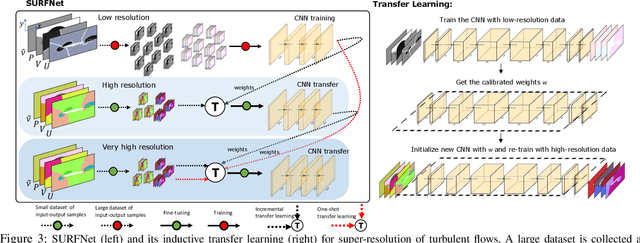

Deep Learning (DL) algorithms are emerging as a key alternative to computationally expensive CFD simulations. However, state-of-the-art DL approaches require large and high-resolution training data to learn accurate models. The size and availability of such datasets are a major limitation for the development of next-generation data-driven surrogate models for turbulent flows. This paper introduces SURFNet, a transfer learning-based super-resolution flow network. SURFNet primarily trains the DL model on low-resolution datasets and transfer learns the model on a handful of high-resolution flow problems - accelerating the traditional numerical solver independent of the input size. We propose two approaches to transfer learning for the task of super-resolution, namely one-shot and incremental learning. Both approaches entail transfer learning on only one geometry to account for fine-grid flow fields requiring 15x less training data on high-resolution inputs compared to the tiny resolution (64x256) of the coarse model, significantly reducing the time for both data collection and training. We empirically evaluate SURFNet's performance by solving the Navier-Stokes equations in the turbulent regime on input resolutions up to 256x larger than the coarse model. On four test geometries and eight flow configurations unseen during training, we observe a consistent 2-2.1x speedup over the OpenFOAM physics solver independent of the test geometry and the resolution size (up to 2048x2048), demonstrating both resolution-invariance and generalization capabilities. Our approach addresses the challenge of reconstructing high-resolution solutions from coarse grid models trained using low-resolution inputs (super-resolution) without loss of accuracy and requiring limited computational resources.