 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Similarity Parameter: A New Machine Learning Loss Metric for Oscillatory Spatio-Temporal Data
Paper and Code
Apr 14, 2022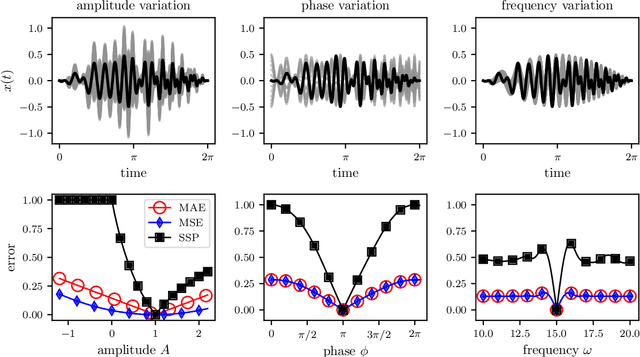
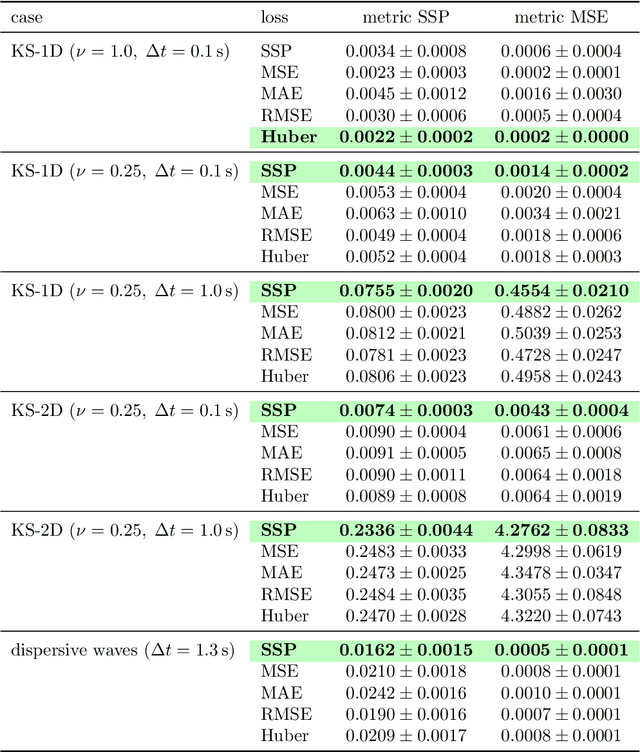
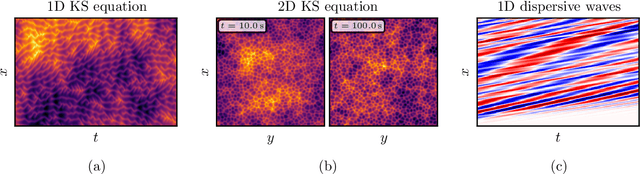

Supervised machine learning approaches require the formulation of a loss functional to be minimized in the training phase. Sequential data are ubiquitous across many fields of research, and are often treated with Euclidean distance-based loss functions that were designed for tabular data. For smooth oscillatory data, those conventional approaches lack the ability to penalize amplitude, frequency and phase prediction errors at the same time, and tend to be biased towards amplitude errors. We introduce the surface similarity parameter (SSP) as a novel loss function that is especially useful for training machine learning models on smooth oscillatory sequences. Our extensive experiments on chaotic spatio-temporal dynamical systems indicate that the SSP is beneficial for shaping gradients, thereby accelerating the training process, reducing the final prediction error, and implementing a stronger regularization effect compared to using classical loss functions. The results indicate the potential of the novel loss metric particularly for highly complex and chaotic data, such as data stemming from the nonlinear two-dimensional Kuramoto-Sivashinsky equation and the linear propagation of dispersive surface gravity waves in fluids.