 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised and Reinforcement Learning from Observations in Reconnaissance Blind Chess
Paper and Code
Aug 03, 2022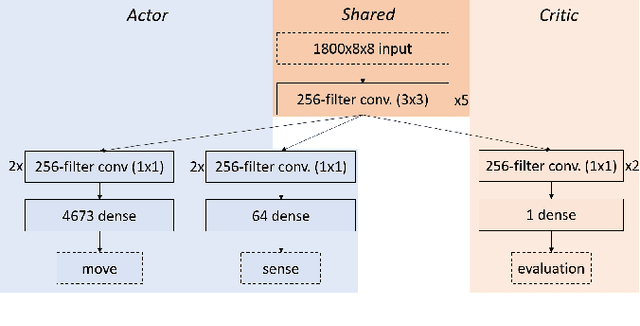
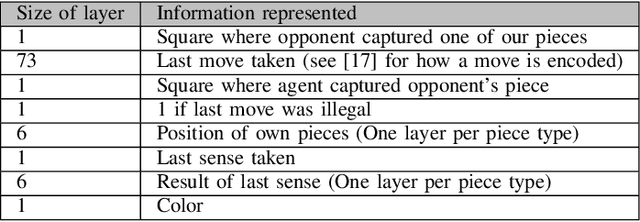
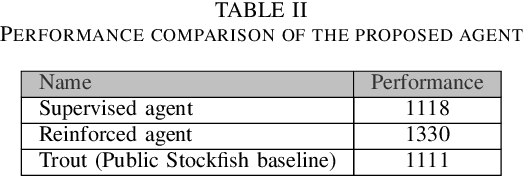
In this work, we adapt a training approach inspired by the original AlphaGo system to play the imperfect information game of Reconnaissance Blind Chess. Using only the observations instead of a full description of the game state, we first train a supervised agent on publicly available game records. Next, we increase the performance of the agent through self-play with the on-policy reinforcement learning algorithm Proximal Policy Optimization. We do not use any search to avoid problems caused by the partial observability of game states and only use the policy network to generate moves when playing. With this approach, we achieve an ELO of 1330 on the RBC leaderboard, which places our agent at position 27 at the time of this writing. We see that self-play significantly improves performance and that the agent plays acceptably well without search and without making assumptions about the true game state.