 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervise Thyself: Examining Self-Supervised Representations in Interactive Environments
Paper and Code
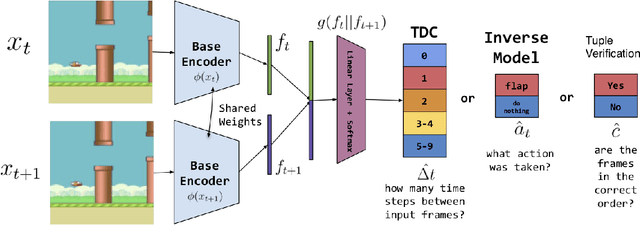

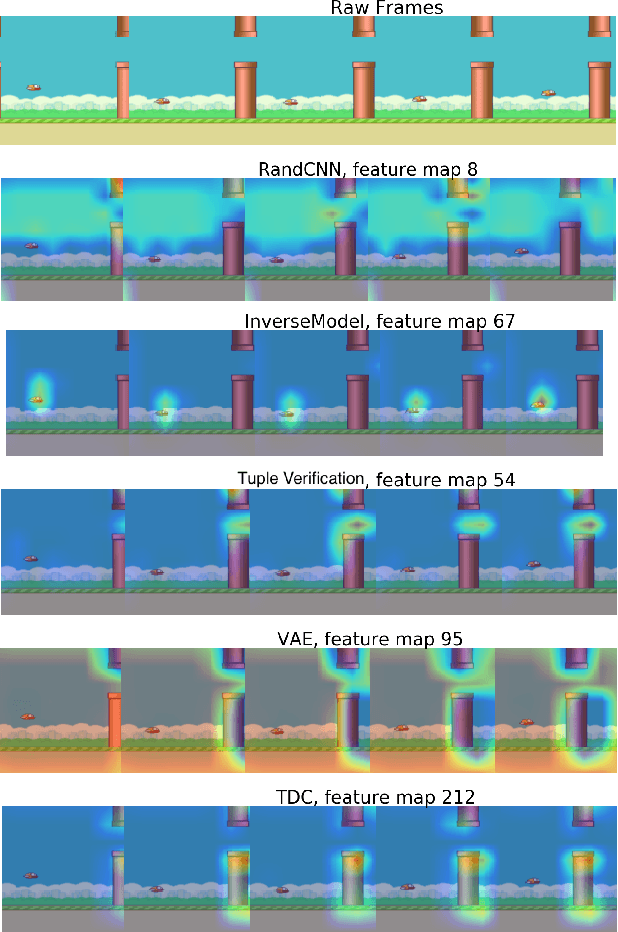

Self-supervised methods, wherein an agent learns representations solely by observing the results of its actions, become crucial in environments which do not provide a dense reward signal or have labels. In most cases, such methods are used for pretraining or auxiliary tasks for "downstream" tasks, such as control, exploration, or imitation learning. However, it is not clear which method's representations best capture meaningful features of the environment, and which are best suited for which types of environments. We present a small-scale study of self-supervised methods on two visual environments: Flappy Bird and Sonic The Hedgehog. In particular, we quantitatively evaluate the representations learned from these tasks in two contexts: a) the extent to which the representations capture true state information of the agent and b) how generalizable these representations are to novel situations, like new levels and textures. Lastly, we evaluate these self-supervised features by visualizing which parts of the environment they focus on. Our results show that the utility of the representations is highly dependent on the visuals and dynamics of the environment.