 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubset Selection with Shrinkage: Sparse Linear Modeling when the SNR is low
Paper and Code
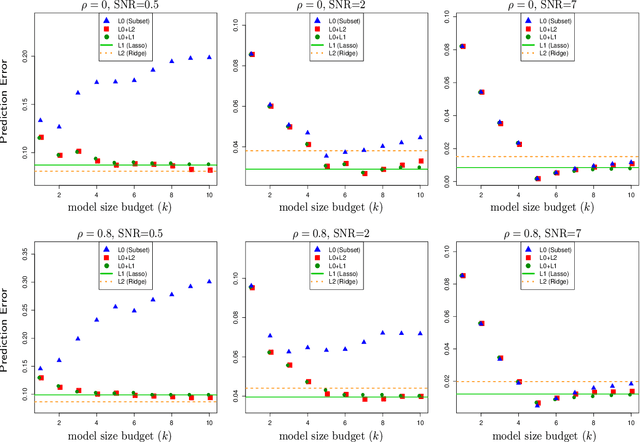

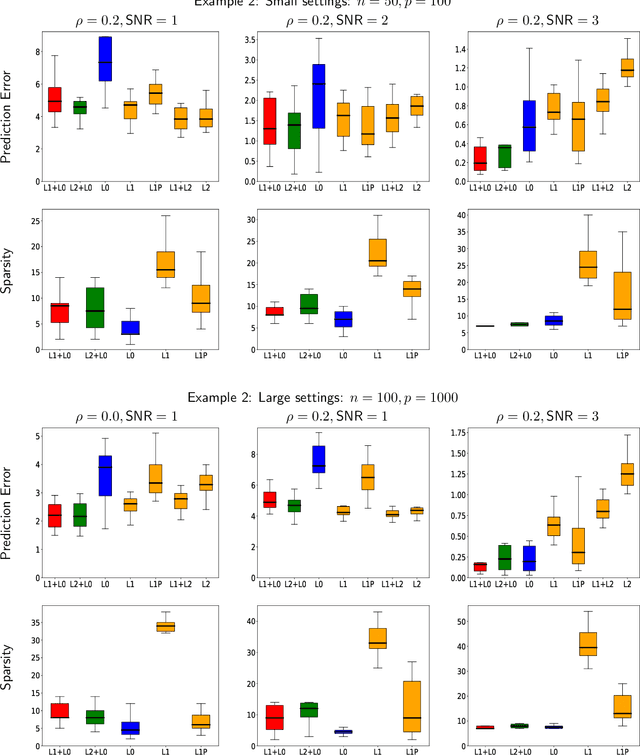
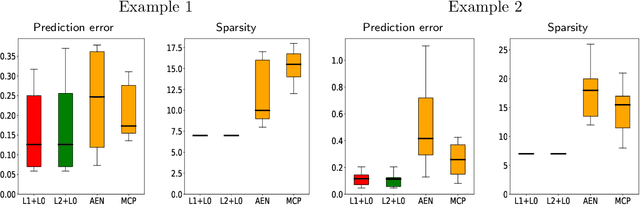
We study the behavior of a fundamental tool in sparse statistical modeling --the best-subset selection procedure (aka "best-subsets"). Assuming that the underlying linear model is sparse, it is well known, both in theory and in practice, that the best-subsets procedure works extremely well in terms of several statistical metrics (prediction, estimation and variable selection) when the signal to noise ratio (SNR) is high. However, its performance degrades substantially when the SNR is low -- it is outperformed in predictive accuracy by continuous shrinkage methods, such as ridge regression and the Lasso. We explain why this behavior should not come as a surprise, and contend that the original version of the classical best-subsets procedure was, perhaps, not designed to be used in the low SNR regimes. We propose a close cousin of best-subsets, namely, its $\ell_{q}$-regularized version, for $q \in\{1, 2\}$, which (a) mitigates, to a large extent, the poor predictive performance of best-subsets in the low SNR regimes; (b) performs favorably and generally delivers a substantially sparser model when compared to the best predictive models available via ridge regression and the Lasso. Our estimator can be expressed as a solution to a mixed integer second order conic optimization problem and, hence, is amenable to modern computational tools from mathematical optimization. We explore the theoretical properties of the predictive capabilities of the proposed estimator and complement our findings via several numerical experiments.