 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleSeg V2: Towards Robust One-shot Segmentation of Brain Tissue via Optimization-free Registration Error Perception
Paper and Code
May 06, 2024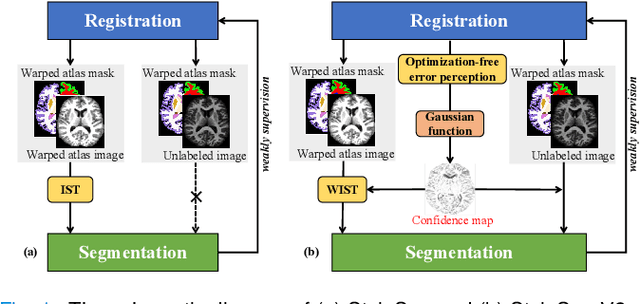
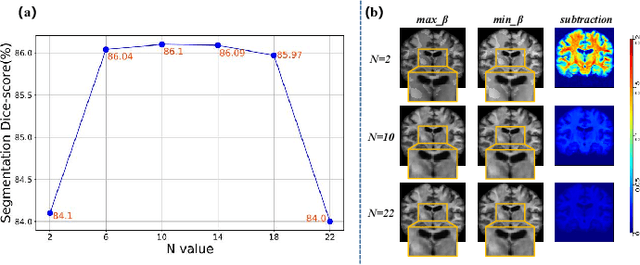
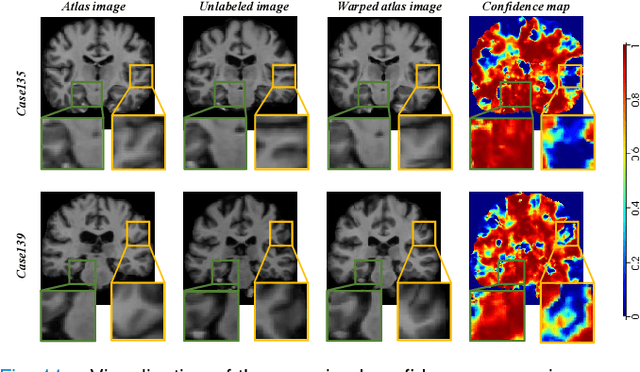
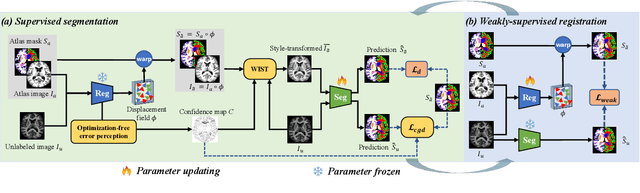
One-shot segmentation of brain tissue requires training registration-segmentation (reg-seg) dual-model iteratively, where reg-model aims to provide pseudo masks of unlabeled images for seg-model by warping a carefully-labeled atlas. However, the imperfect reg-model induces image-mask misalignment, poisoning the seg-model subsequently. Recent StyleSeg bypasses this bottleneck by replacing the unlabeled images with their warped copies of atlas, but needs to borrow the diverse image patterns via style transformation. Here, we present StyleSeg V2, inherited from StyleSeg but granted the ability of perceiving the registration errors. The motivation is that good registration behaves in a mirrored fashion for mirrored images. Therefore, almost at no cost, StyleSeg V2 can have reg-model itself "speak out" incorrectly-aligned regions by simply mirroring (symmetrically flipping the brain) its input, and the registration errors are symmetric inconsistencies between the outputs of original and mirrored inputs. Consequently, StyleSeg V2 allows the seg-model to make use of correctly-aligned regions of unlabeled images and also enhances the fidelity of style-transformed warped atlas image by weighting the local transformation strength according to registration errors. The experimental results on three public datasets demonstrate that our proposed StyleSeg V2 outperforms other state-of-the-arts by considerable margins, and exceeds StyleSeg by increasing the average Dice by at least 2.4%.