 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylePrompter: All Styles Need Is Attention
Paper and Code


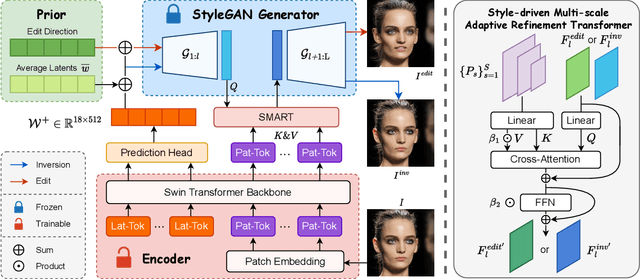

GAN inversion aims at inverting given images into corresponding latent codes for Generative Adversarial Networks (GANs), especially StyleGAN where exists a disentangled latent space that allows attribute-based image manipulation at latent level. As most inversion methods build upon Convolutional Neural Networks (CNNs), we transfer a hierarchical vision Transformer backbone innovatively to predict $\mathcal{W^+}$ latent codes at token level. We further apply a Style-driven Multi-scale Adaptive Refinement Transformer (SMART) in $\mathcal{F}$ space to refine the intermediate style features of the generator. By treating style features as queries to retrieve lost identity information from the encoder's feature maps, SMART can not only produce high-quality inverted images but also surprisingly adapt to editing tasks. We then prove that StylePrompter lies in a more disentangled $\mathcal{W^+}$ and show the controllability of SMART. Finally, quantitative and qualitative experiments demonstrate that StylePrompter can achieve desirable performance in balancing reconstruction quality and editability, and is "smart" enough to fit into most edits, outperforming other $\mathcal{F}$-involved inversion methods.