 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Voronoi Sampling
Paper and Code
Jun 05, 2023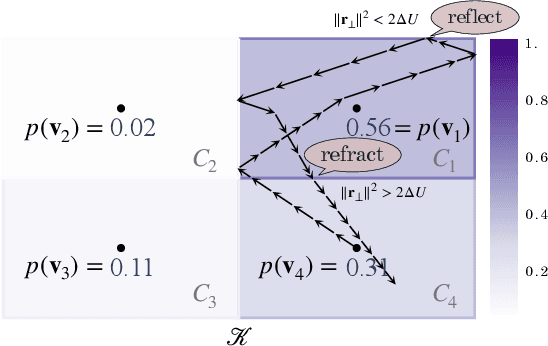



Recently, there has been a growing interest in the development of gradient-based sampling algorithms for text generation, especially in the context of controlled generation. However, there exists a lack of theoretically grounded and principled approaches for this task. In this paper, we take an important step toward building a principled approach for sampling from language models with gradient-based methods. We use discrete distributions given by language models to define densities and develop an algorithm based on Hamiltonian Monte Carlo to sample from them. We name our gradient-based technique Structured Voronoi Sampling (SVS). In an experimental setup where the reference distribution is known, we show that the empirical distribution of SVS samples is closer to the reference distribution compared to alternative sampling schemes. Furthermore, in a controlled generation task, SVS is able to generate fluent and diverse samples while following the control targets significantly better than other methods.