 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Sparse Ternary Weight Coding of Deep Neural Networks for Efficient Hardware Implementations
Paper and Code
Jul 01, 2017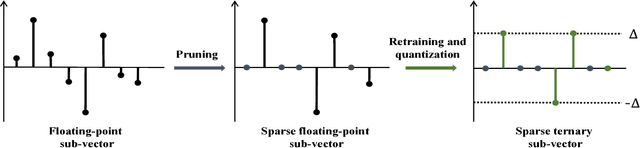
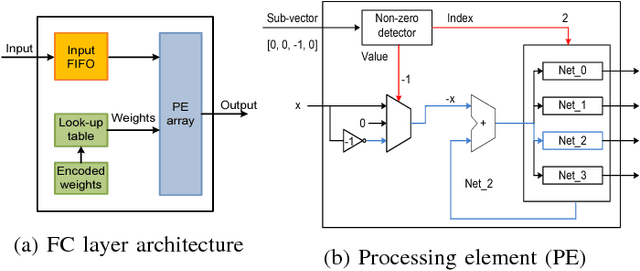


Deep neural networks (DNNs) usually demand a large amount of operations for real-time inference. Especially, fully-connected layers contain a large number of weights, thus they usually need many off-chip memory accesses for inference. We propose a weight compression method for deep neural networks, which allows values of +1 or -1 only at predetermined positions of the weights so that decoding using a table can be conducted easily. For example, the structured sparse (8,2) coding allows at most two non-zero values among eight weights. This method not only enables multiplication-free DNN implementations but also compresses the weight storage by up to x32 compared to floating-point networks. Weight distribution normalization and gradual pruning techniques are applied to mitigate the performance degradation. The experiments are conducted with fully-connected deep neural networks and convolutional neural networks.