 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Transformer for Graph Representation Learning
Paper and Code

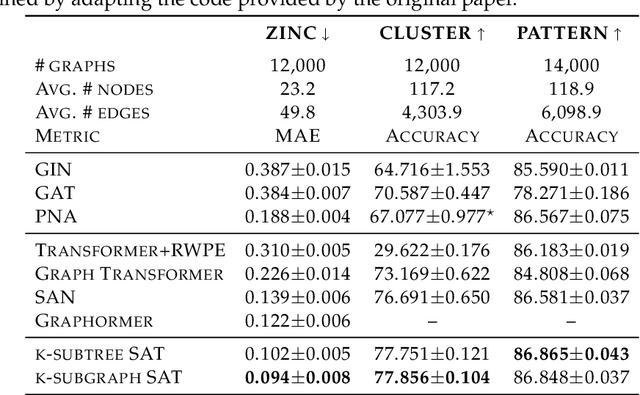
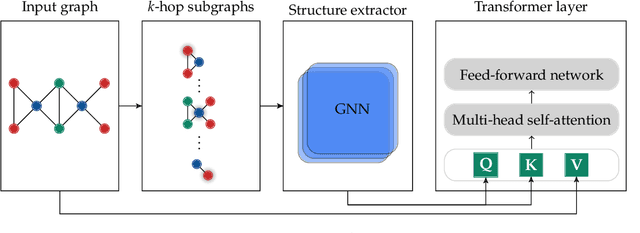
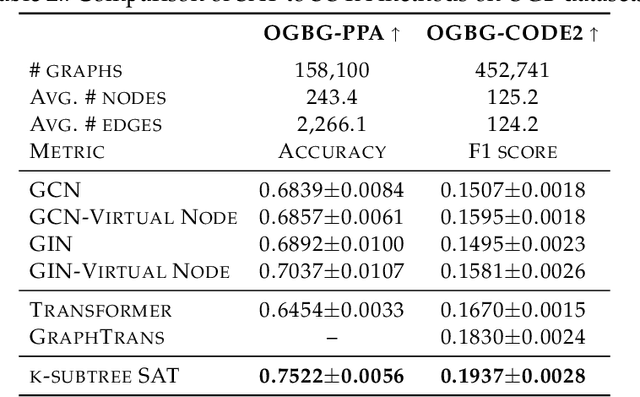
The Transformer architecture has gained growing attention in graph representation learning recently, as it naturally overcomes several limitations of graph neural networks (GNNs) by avoiding their strict structural inductive biases and instead only encoding the graph structure via positional encoding. Here, we show that the node representations generated by the Transformer with positional encoding do not necessarily capture structural similarity between them. To address this issue, we propose the Structure-Aware Transformer, a class of simple and flexible graph transformers built upon a new self-attention mechanism. This new self-attention incorporates structural information into the original self-attention by extracting a subgraph representation rooted at each node before computing the attention. We propose several methods for automatically generating the subgraph representation and show theoretically that the resulting representations are at least as expressive as the subgraph representations. Empirically, our method achieves state-of-the-art performance on five graph prediction benchmarks. Our structure-aware framework can leverage any existing GNN to extract the subgraph representation, and we show that it systematically improves performance relative to the base GNN model, successfully combining the advantages of GNNs and transformers.