 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure and inference in annotated networks
Paper and Code
Jul 14, 2015

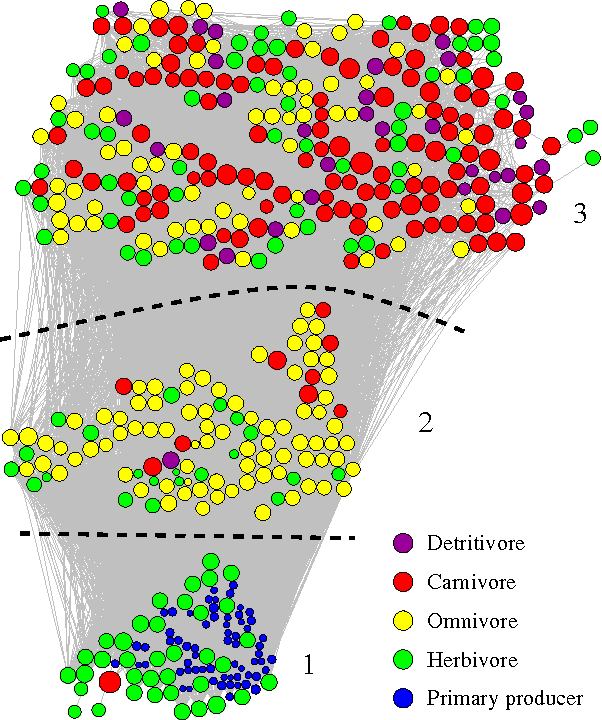
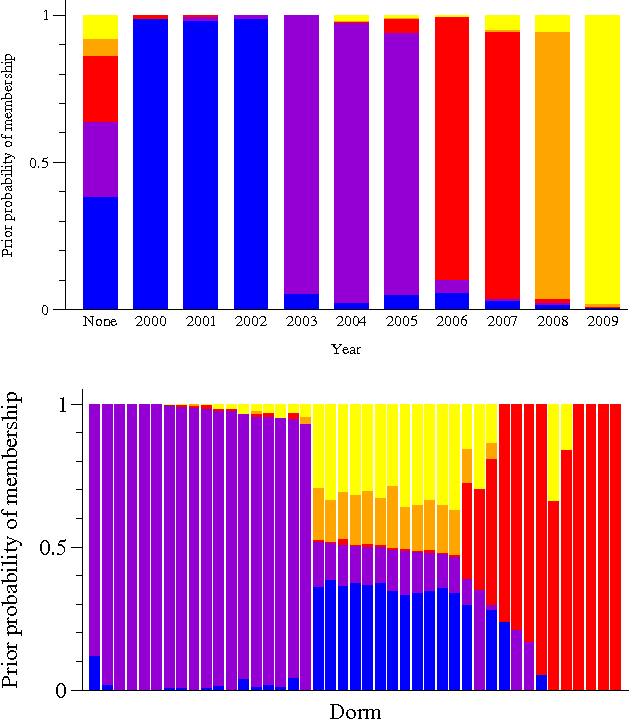
For many networks of scientific interest we know both the connections of the network and information about the network nodes, such as the age or gender of individuals in a social network, geographic location of nodes in the Internet, or cellular function of nodes in a gene regulatory network. Here we demonstrate how this "metadata" can be used to improve our analysis and understanding of network structure. We focus in particular on the problem of community detection in networks and develop a mathematically principled approach that combines a network and its metadata to detect communities more accurately than can be done with either alone. Crucially, the method does not assume that the metadata are correlated with the communities we are trying to find. Instead the method learns whether a correlation exists and correctly uses or ignores the metadata depending on whether they contain useful information. The learned correlations are also of interest in their own right, allowing us to make predictions about the community membership of nodes whose network connections are unknown. We demonstrate our method on synthetic networks with known structure and on real-world networks, large and small, drawn from social, biological, and technological domains.