 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger, Faster and More Explainable: A Graph Convolutional Baseline for Skeleton-based Action Recognition
Paper and Code
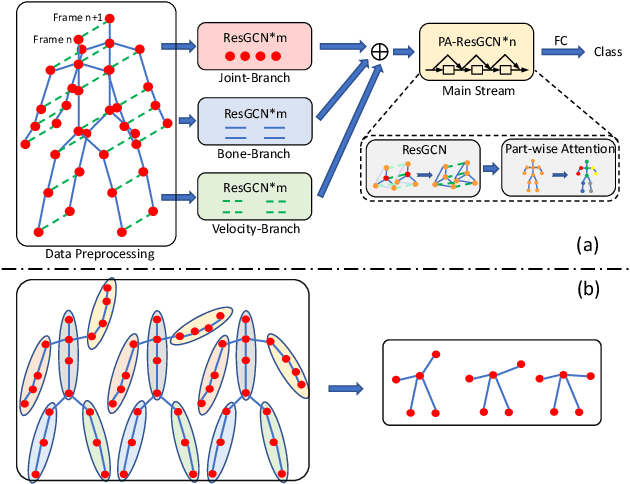

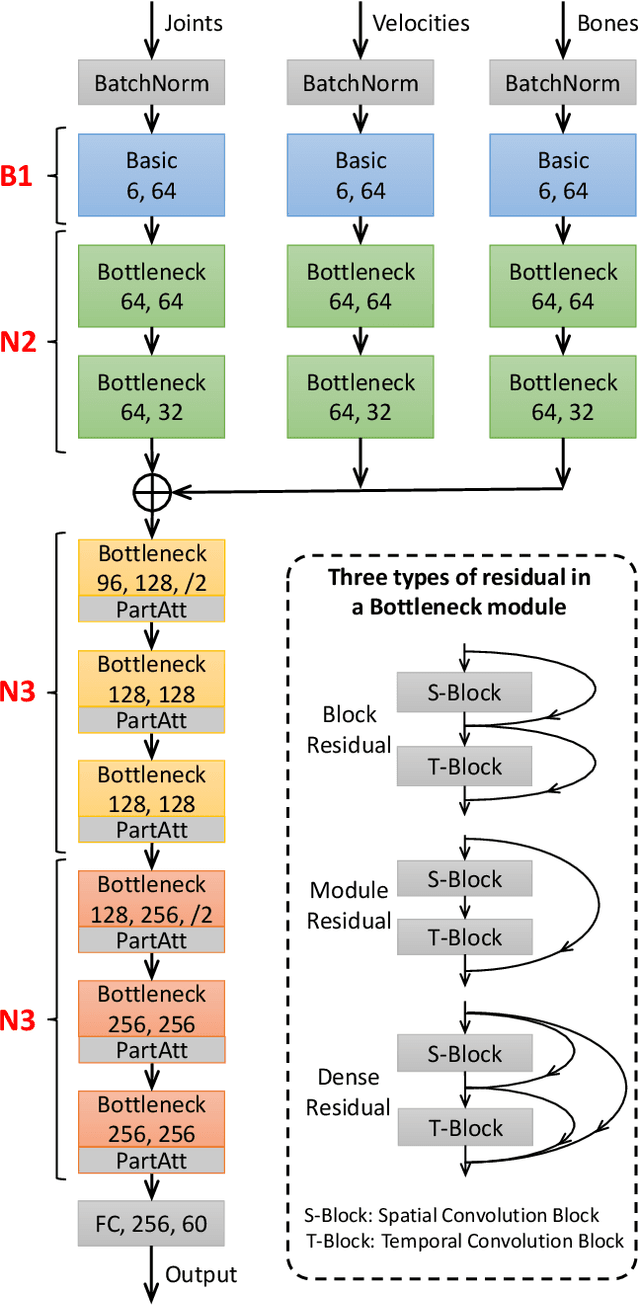

One essential problem in skeleton-based action recognition is how to extract discriminative features over all skeleton joints. However, the complexity of the State-Of-The-Art (SOTA) models of this task tends to be exceedingly sophisticated and over-parameterized, where the low efficiency in model training and inference has obstructed the development in the field, especially for large-scale action datasets. In this work, we propose an efficient but strong baseline based on Graph Convolutional Network (GCN), where three main improvements are aggregated, i.e., early fused Multiple Input Branches (MIB), Residual GCN (ResGCN) with bottleneck structure and Part-wise Attention (PartAtt) block. Firstly, an MIB is designed to enrich informative skeleton features and remain compact representations at an early fusion stage. Then, inspired by the success of the ResNet architecture in Convolutional Neural Network (CNN), a ResGCN module is introduced in GCN to alleviate computational costs and reduce learning difficulties in model training while maintain the model accuracy. Finally, a PartAtt block is proposed to discover the most essential body parts over a whole action sequence and obtain more explainable representations for different skeleton action sequences. Extensive experiments on two large-scale datasets, i.e., NTU RGB+D 60 and 120, validate that the proposed baseline slightly outperforms other SOTA models and meanwhile requires much fewer parameters during training and inference procedures, e.g., at most 34 times less than DGNN, which is one of the best SOTA methods.