 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for Arabic Readability Modeling
Paper and Code
Jul 03, 2024
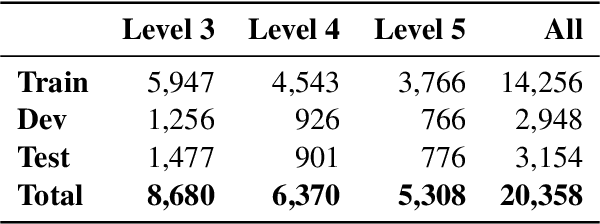


Automatic readability assessment is relevant to building NLP applications for education, content analysis, and accessibility. However, Arabic readability assessment is a challenging task due to Arabic's morphological richness and limited readability resources. In this paper, we present a set of experimental results on Arabic readability assessment using a diverse range of approaches, from rule-based methods to Arabic pretrained language models. We report our results on a newly created corpus at different textual granularity levels (words and sentence fragments). Our results show that combining different techniques yields the best results, achieving an overall macro F1 score of 86.7 at the word level and 87.9 at the fragment level on a blind test set. We make our code, data, and pretrained models publicly available.