 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic WaveNet: A Generative Latent Variable Model for Sequential Data
Paper and Code
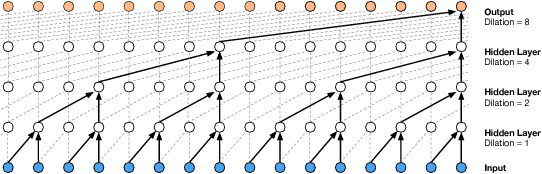
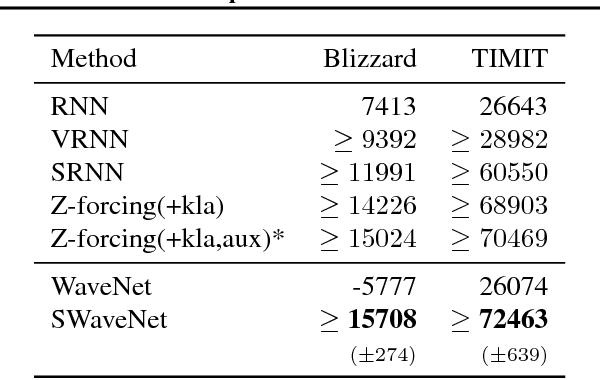
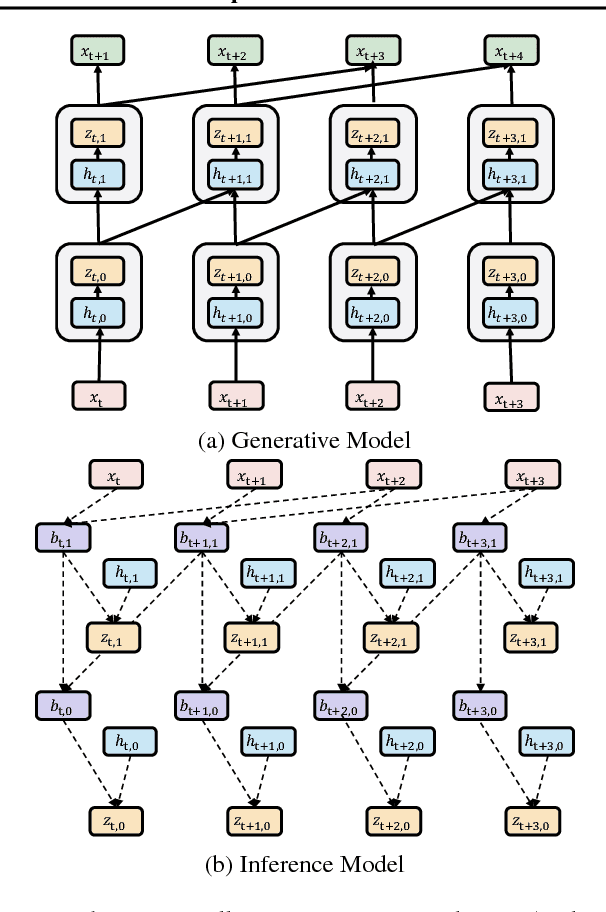

How to model distribution of sequential data, including but not limited to speech and human motions, is an important ongoing research problem. It has been demonstrated that model capacity can be significantly enhanced by introducing stochastic latent variables in the hidden states of recurrent neural networks. Simultaneously, WaveNet, equipped with dilated convolutions, achieves astonishing empirical performance in natural speech generation task. In this paper, we combine the ideas from both stochastic latent variables and dilated convolutions, and propose a new architecture to model sequential data, termed as Stochastic WaveNet, where stochastic latent variables are injected into the WaveNet structure. We argue that Stochastic WaveNet enjoys powerful distribution modeling capacity and the advantage of parallel training from dilated convolutions. In order to efficiently infer the posterior distribution of the latent variables, a novel inference network structure is designed based on the characteristics of WaveNet architecture. State-of-the-art performances on benchmark datasets are obtained by Stochastic WaveNet on natural speech modeling and high quality human handwriting samples can be generated as well.