 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Runge-Kutta methods and adaptive SGD-G2 stochastic gradient descent
Paper and Code
Feb 20, 2020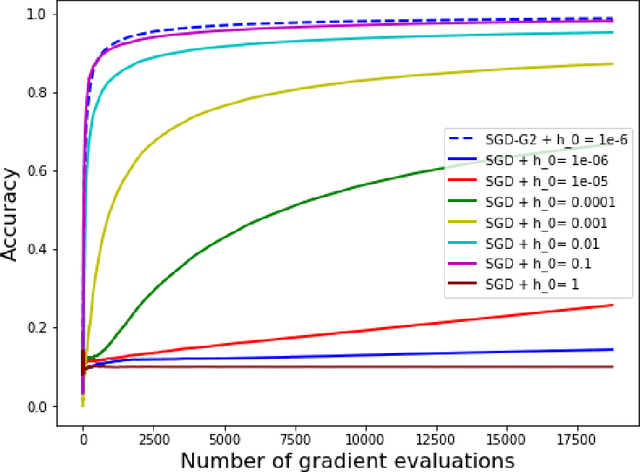
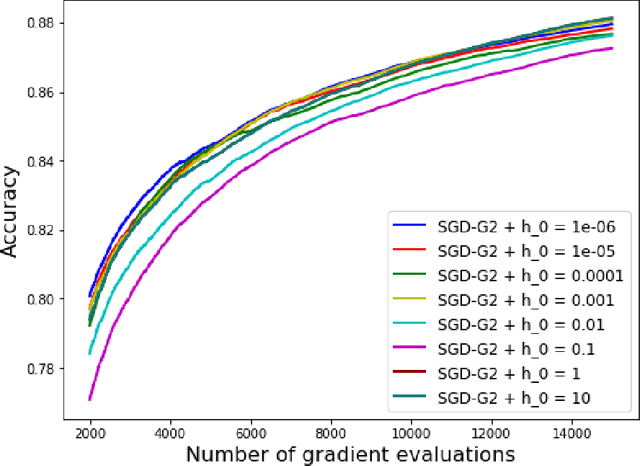
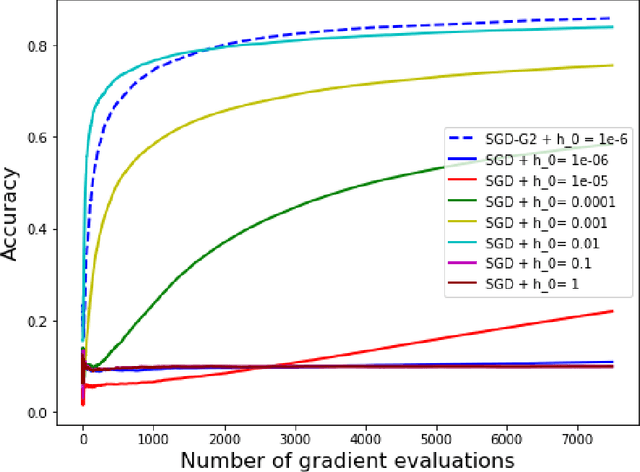
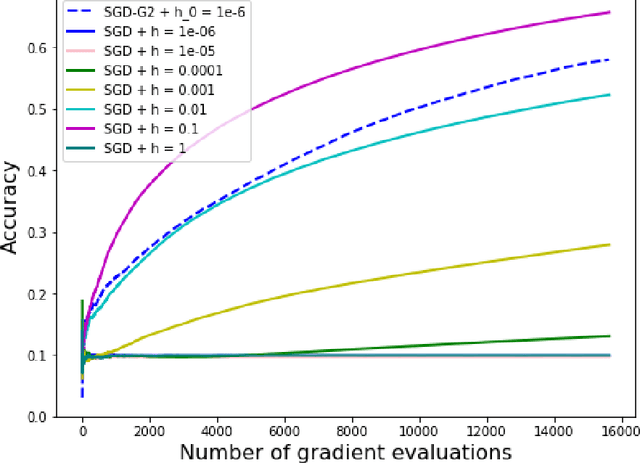
The minimization of the loss function is of paramount importance in deep neural networks. On the other hand, many popular optimization algorithms have been shown to correspond to some evolution equation of gradient flow type. Inspired by the numerical schemes used for general evolution equations we introduce a second order stochastic Runge Kutta method and show that it yields a consistent procedure for the minimization of the loss function. In addition it can be coupled, in an adaptive framework, with a Stochastic Gradient Descent (SGD) to adjust automatically the learning rate of the SGD, without the need of any additional information on the Hessian of the loss functional. The adaptive SGD, called SGD-G2, is successfully tested on standard datasets.