Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Polyak Stepsize with a Moving Target
Paper and Code
Jun 22, 2021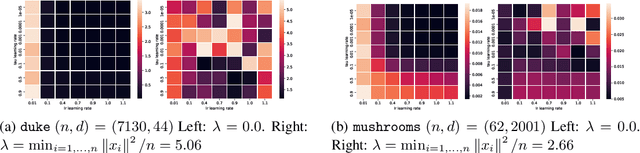

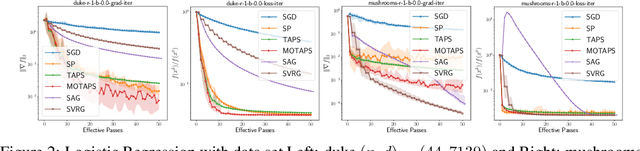
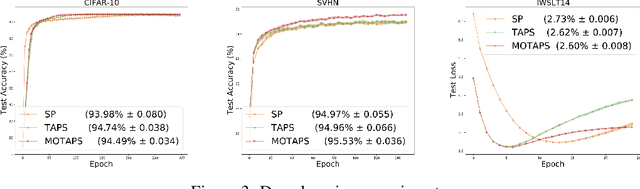
We propose a new stochastic gradient method that uses recorded past loss values to reduce the variance. Our method can be interpreted as a new stochastic variant of the Polyak Stepsize that converges globally without assuming interpolation. Our method introduces auxiliary variables, one for each data point, that track the loss value for each data point. We provide a global convergence theory for our method by showing that it can be interpreted as a special variant of online SGD. The new method only stores a single scalar per data point, opening up new applications for variance reduction where memory is the bottleneck.
* 41 pages, 13 figures, 1 table
View paper on