 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Optimization from Distributed, Streaming Data in Rate-limited Networks
Paper and Code
Aug 06, 2018
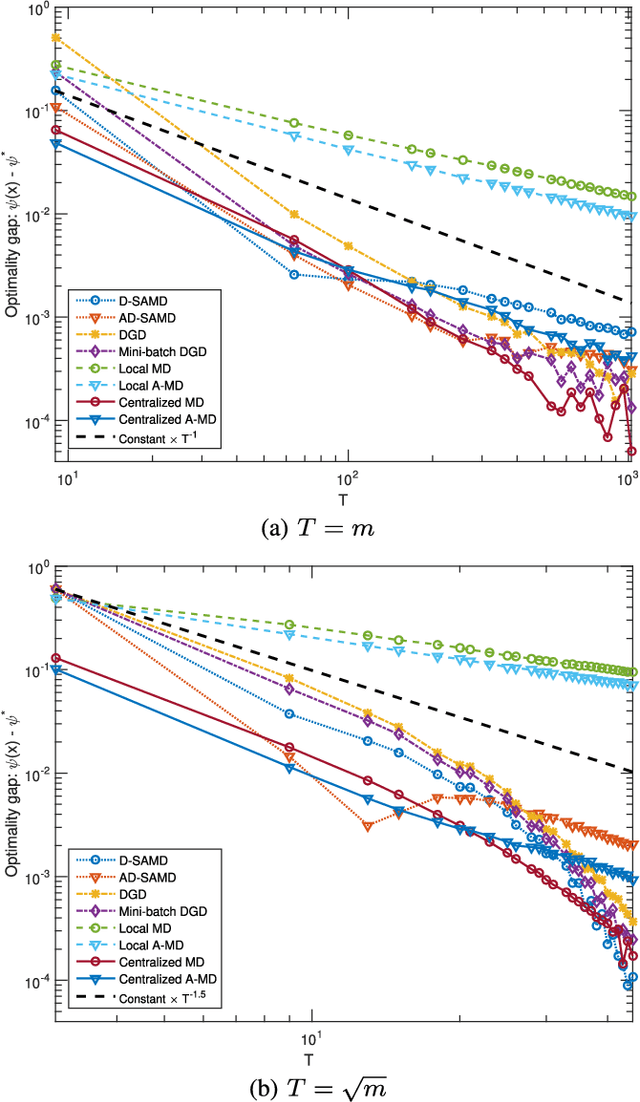
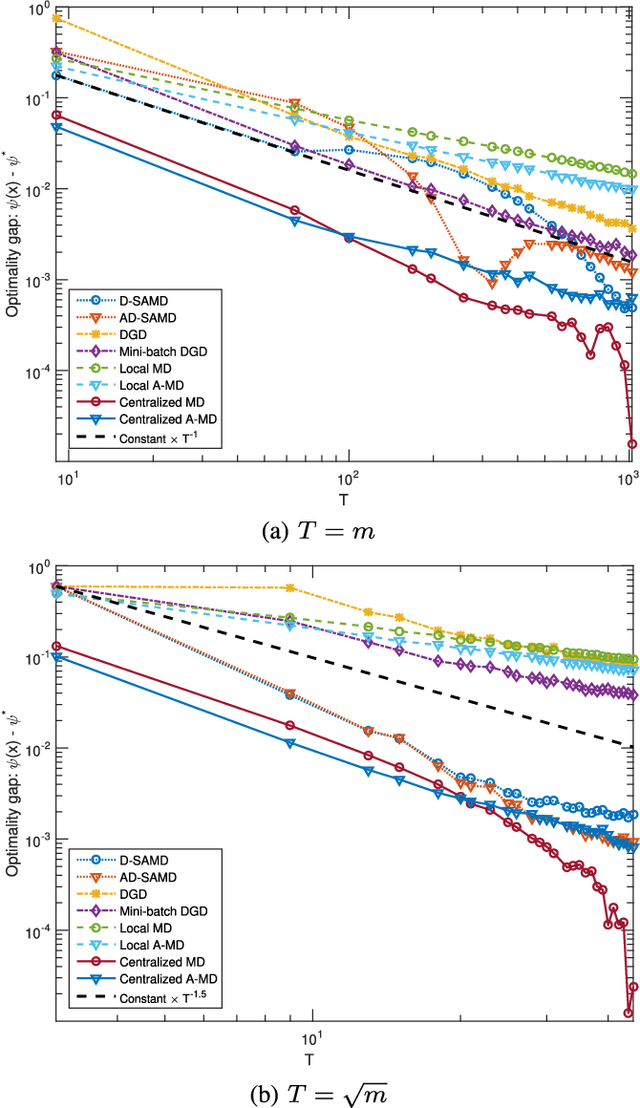
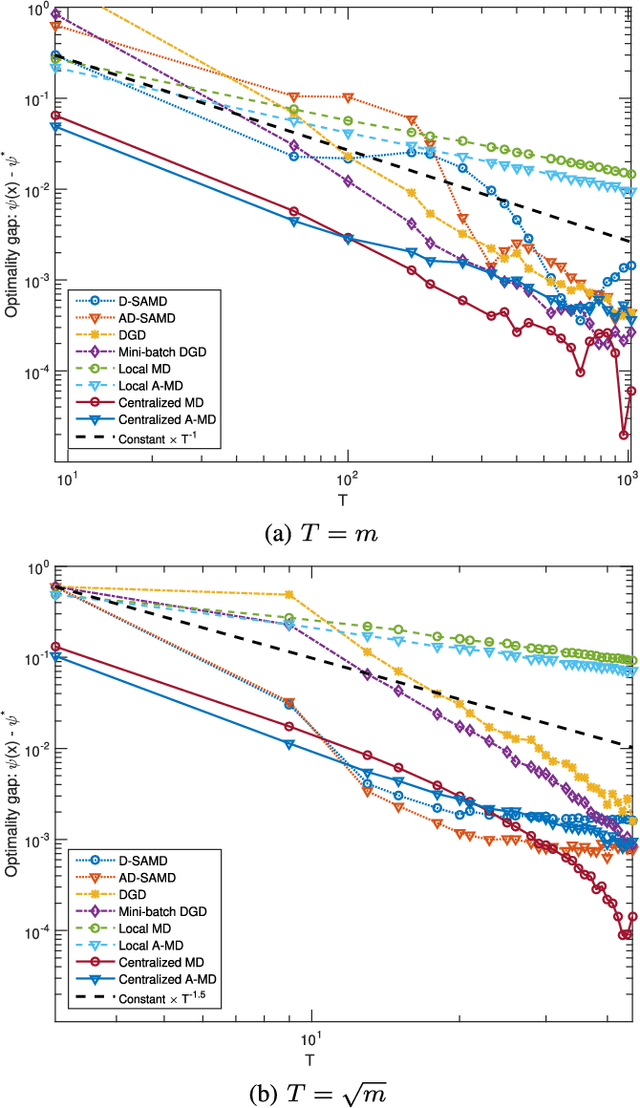
Motivated by machine learning applications in networks of sensors, internet-of-things (IoT) devices, and autonomous agents, we propose techniques for distributed stochastic convex learning from high-rate data streams. The setup involves a network of nodes---each one of which has a stream of data arriving at a constant rate---that solve a stochastic convex optimization problem by collaborating with each other over rate-limited communication links. To this end, we present and analyze two algorithms---termed distributed stochastic approximation mirror descent (D-SAMD) and accelerated distributed stochastic approximation mirror descent (AD-SAMD)---that are based on two stochastic variants of mirror descent and in which nodes collaborate via approximate averaging of the local, noisy subgradients using distributed consensus. Our main contributions are (i) bounds on the convergence rates of D-SAMD and AD-SAMD in terms of the number of nodes, network topology, and ratio of the data streaming and communication rates, and (ii) sufficient conditions for order-optimum convergence of these algorithms. In particular, we show that for sufficiently well-connected networks, distributed learning schemes can obtain order-optimum convergence even if the communications rate is small. Further we find that the use of accelerated methods significantly enlarges the regime in which order-optimum convergence is achieved; this is in contrast to the centralized setting, where accelerated methods usually offer only a modest improvement. Finally, we demonstrate the effectiveness of the proposed algorithms using numerical experiments.