 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Natural Language Generation Using Dependency Information
Paper and Code

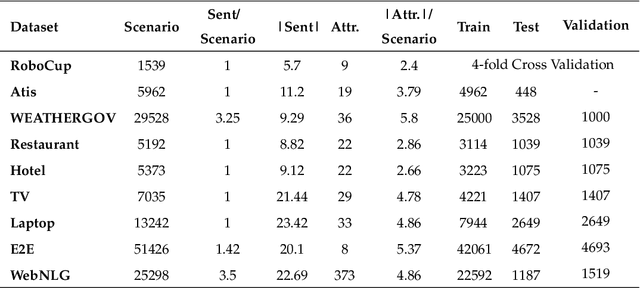
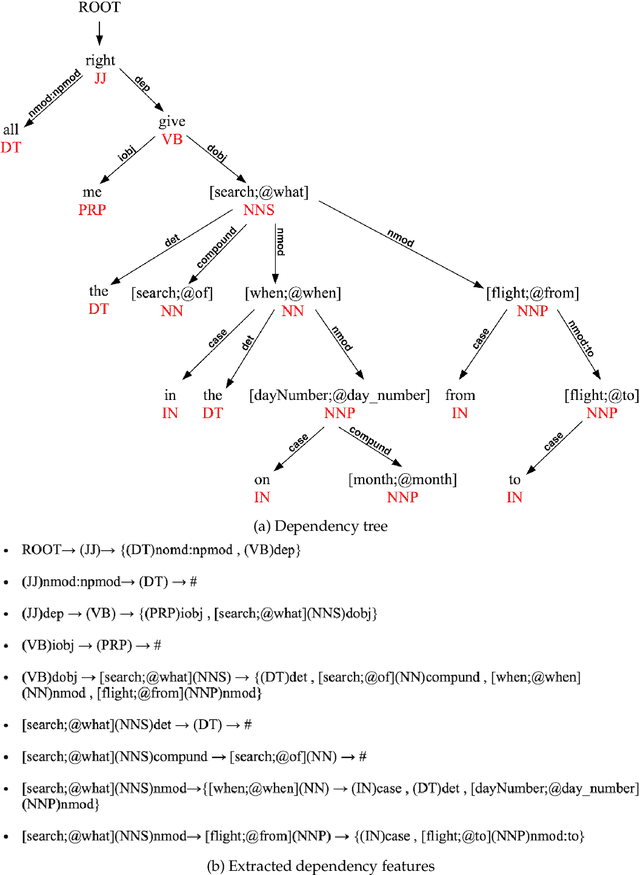

This article presents a stochastic corpus-based model for generating natural language text. Our model first encodes dependency relations from training data through a feature set, then concatenates these features to produce a new dependency tree for a given meaning representation, and finally generates a natural language utterance from the produced dependency tree. We test our model on nine domains from tabular, dialogue act and RDF format. Our model outperforms the corpus-based state-of-the-art methods trained on tabular datasets and also achieves comparable results with neural network-based approaches trained on dialogue act, E2E and WebNLG datasets for BLEU and ERR evaluation metrics. Also, by reporting Human Evaluation results, we show that our model produces high-quality utterances in aspects of informativeness and naturalness as well as quality.