 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic model for the vocabulary growth in natural languages
Paper and Code
Apr 04, 2013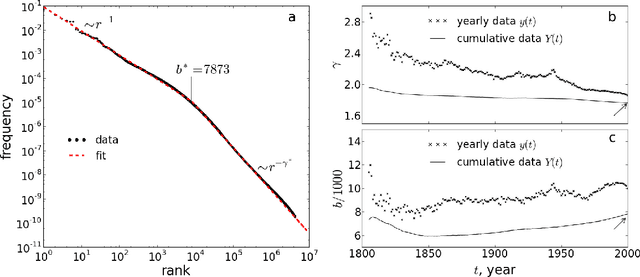
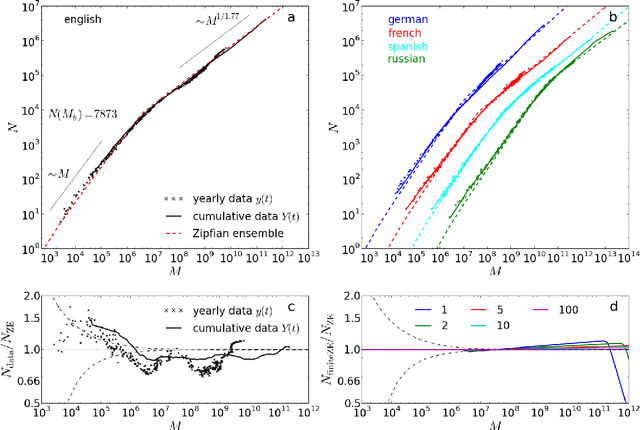


We propose a stochastic model for the number of different words in a given database which incorporates the dependence on the database size and historical changes. The main feature of our model is the existence of two different classes of words: (i) a finite number of core-words which have higher frequency and do not affect the probability of a new word to be used; and (ii) the remaining virtually infinite number of noncore-words which have lower frequency and once used reduce the probability of a new word to be used in the future. Our model relies on a careful analysis of the google-ngram database of books published in the last centuries and its main consequence is the generalization of Zipf's and Heaps' law to two scaling regimes. We confirm that these generalizations yield the best simple description of the data among generic descriptive models and that the two free parameters depend only on the language but not on the database. From the point of view of our model the main change on historical time scales is the composition of the specific words included in the finite list of core-words, which we observe to decay exponentially in time with a rate of approximately 30 words per year for English.