 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent on Separable Data: Exact Convergence with a Fixed Learning Rate
Paper and Code
Jun 05, 2018
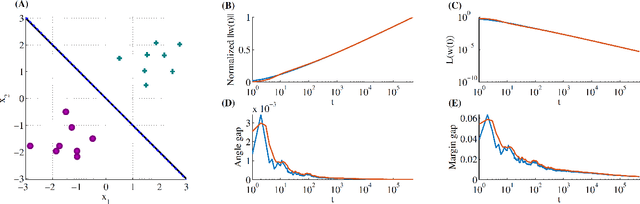
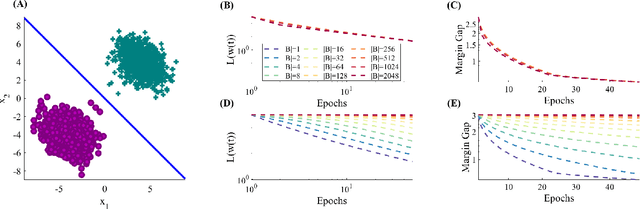
Stochastic Gradient Descent (SGD) is a central tool in machine learning. We prove that SGD converges to zero loss, even with a fixed learning rate --- in the special case of linear classifiers with smooth monotone loss functions, optimized on linearly separable data. Previous proofs with an exact asymptotic convergence of SGD required a learning rate that asymptotically vanishes to zero, or averaging of the SGD iterates. Furthermore, if the loss function has an exponential tail (e.g., logistic regression), then we prove that with SGD the weight vector converges in direction to the $L_2$ max margin vector as $O(1/\log(t))$ for almost all separable datasets, and the loss converges as $O(1/t)$ --- similarly to gradient descent. These results suggest an explanation to the similar behavior observed in deep networks when trained with SGD.