Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic dual averaging methods using variance reduction techniques for regularized empirical risk minimization problems
Paper and Code
Mar 08, 2016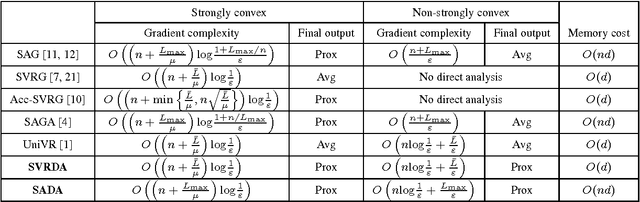
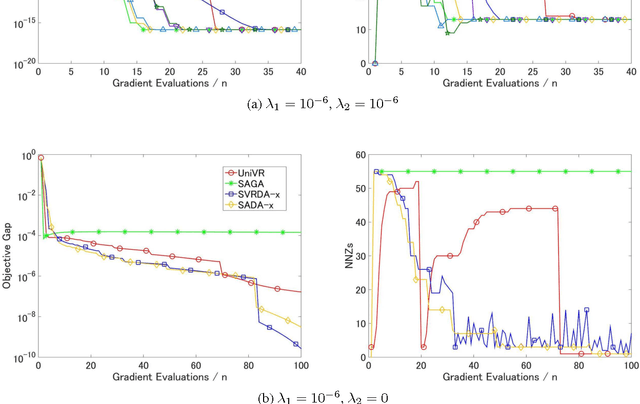
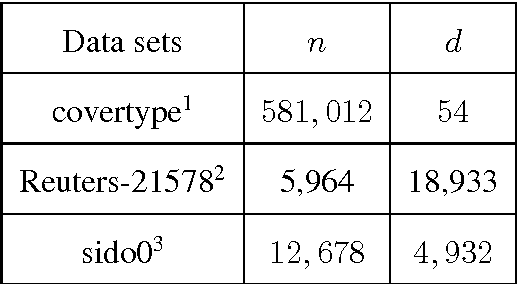
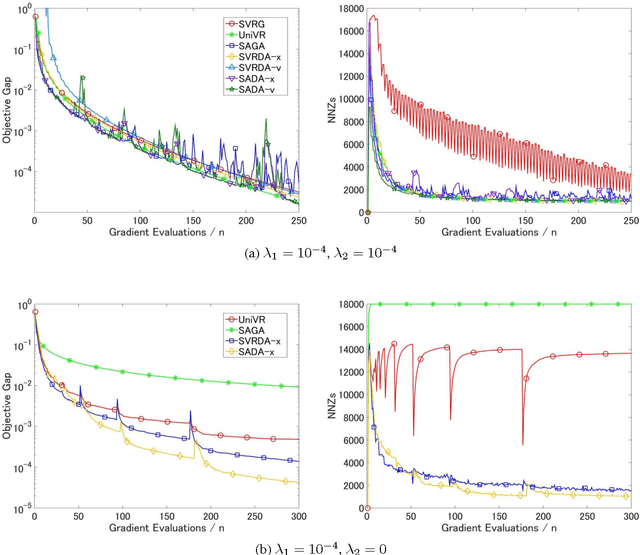
We consider a composite convex minimization problem associated with regularized empirical risk minimization, which often arises in machine learning. We propose two new stochastic gradient methods that are based on stochastic dual averaging method with variance reduction. Our methods generate a sparser solution than the existing methods because we do not need to take the average of the history of the solutions. This is favorable in terms of both interpretability and generalization. Moreover, our methods have theoretical support for both a strongly and a non-strongly convex regularizer and achieve the best known convergence rates among existing nonaccelerated stochastic gradient methods.
* 30 pages, 12 figures
View paper on