 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Mechanics of Generalization in Kernel Regression
Paper and Code


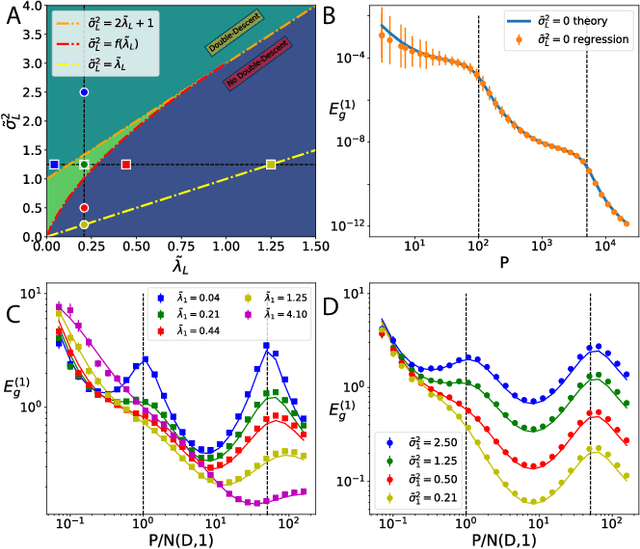
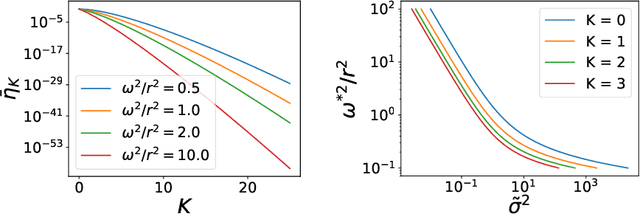
Generalization beyond a training dataset is a main goal of machine learning. We investigate generalization error in kernel regression using statistical mechanics and derive an analytical expression for it applicable to any kernel. Focusing on the broad class of rotation invariant kernels, which is relevant to training deep neural networks in the infinite-width limit, we show several phenomena. When data is drawn from a spherically symmetric distribution and the number of input dimensions, $D$, is large, we find that multiple learning stages exist, one for each scaling of the number of training samples with $\mathcal{O}_D(D^K)$ with $K\in Z^+$. In each stage $\mathcal{O}_D(D^K)$ degenerate spectral modes corresponding to the $K$-th kernel eigenvalue are learned. The mathematical analysis of a learning stage reduces to that of a solvable model with the dimensionality of the feature space extensive in the number of samples and a white kernel spectrum, including linear regression as a special case. The behavior of the learning curve in each stage is governed by an effective regularizer and an effective target noise that are related to the tail of the kernel and the target function spectra. When effective regularization is zero, we identify a first order phase transition that corresponds to a divergence in the generalization error. Each learning stage can exhibit sample-wise \textit{double-descent}, where learning curves show non-monotonic sample size dependence. For each stage an optimal value of effective regularizer exists, equal to the effective noise variance, that gives minimum generalization error.