 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Linear Models in Virus Genomic Alignment-free Classification: Application to Hepatitis C Viruses
Paper and Code
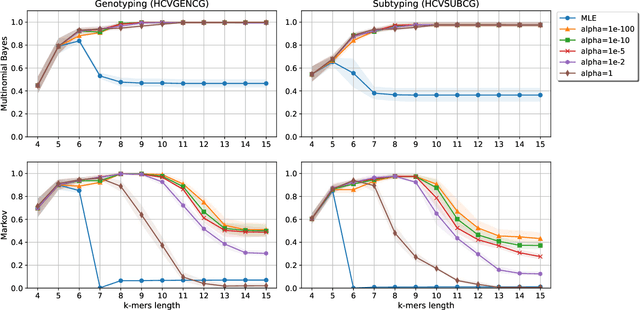
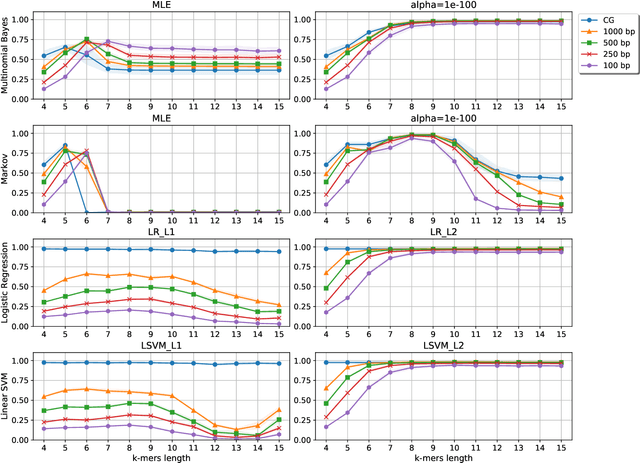
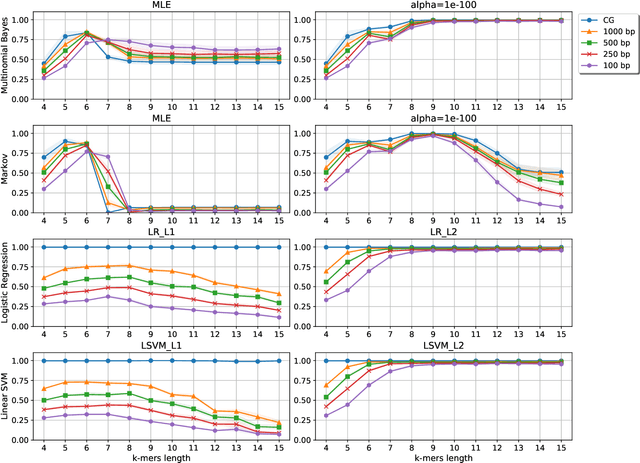

Viral sequence classification is an important task in pathogen detection, epidemiological surveys and evolutionary studies. Statistical learning methods are widely used to classify and identify viral sequences in samples from environments. These methods face several challenges associated with the nature and properties of viral genomes such as recombination, mutation rate and diversity. Also, new generations of sequencing technologies rise other difficulties by generating massive amounts of fragmented sequences. While linear classifiers are often used to classify viruses, there is a lack of exploration of the accuracy space of existing models in the context of alignment free approaches. In this study, we present an exhaustive assessment procedure exploring the power of linear classifiers in genotyping and subtyping partial and complete genomes. It is applied to the Hepatitis C viruses (HCV). Several variables are considered in this investigation such as classifier types (generative and discriminative) and their hyper-parameters (smoothing value and regularization penalty function), the classification task (genotyping and subtyping), the length of the tested sequences (partial and complete) and the length of k-mer words. Overall, several classifiers perform well given a set of precise combination of the experimental variables mentioned above. Finally, we provide the procedure and benchmark data to allow for more robust assessment of classification from virus genomes.