 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Aspects of SHAP: Functional ANOVA for Model Interpretation
Paper and Code
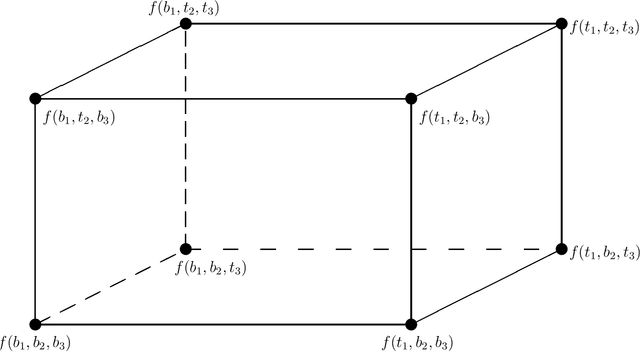
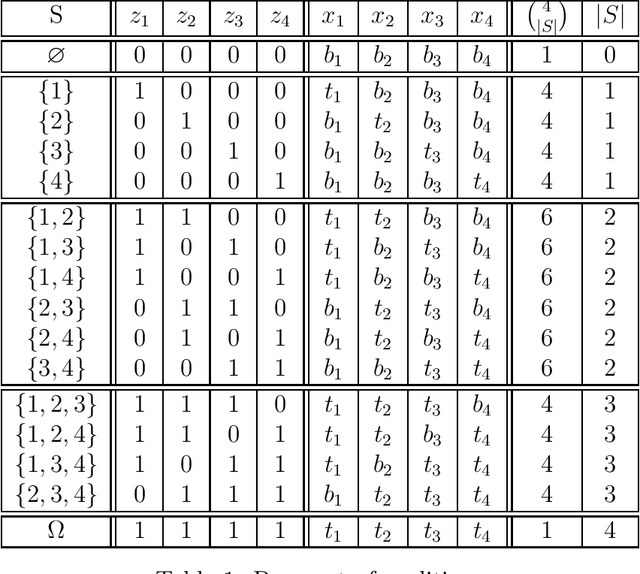
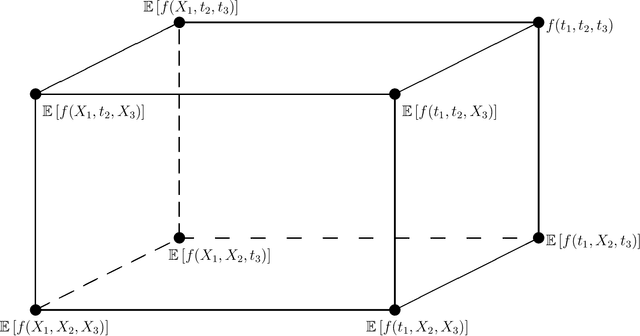
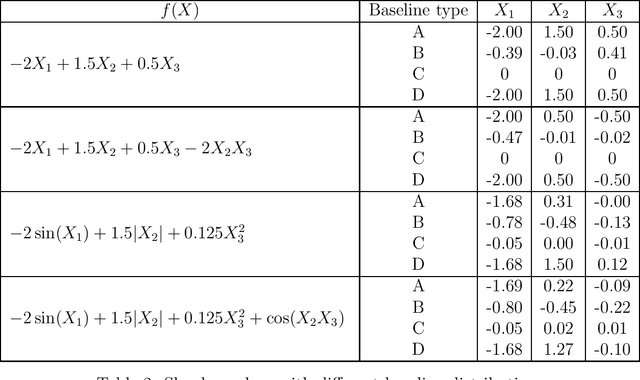
SHAP is a popular method for measuring variable importance in machine learning models. In this paper, we study the algorithm used to estimate SHAP scores and show that it is a transformation of the functional ANOVA decomposition. We use this connection to show that challenges in SHAP approximations largely relate to the choice of a feature distribution and the number of $2^p$ ANOVA terms estimated. We argue that the connection between machine learning explainability and sensitivity analysis is illuminating in this case, but the immediate practical consequences are not obvious since the two fields face a different set of constraints. Machine learning explainability concerns models which are inexpensive to evaluate but often have hundreds, if not thousands, of features. Sensitivity analysis typically deals with models from physics or engineering which may be very time consuming to run, but operate on a comparatively small space of inputs.