 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR-Net: Action Recognition using Spatio-Temporal Activation Reprojection
Paper and Code
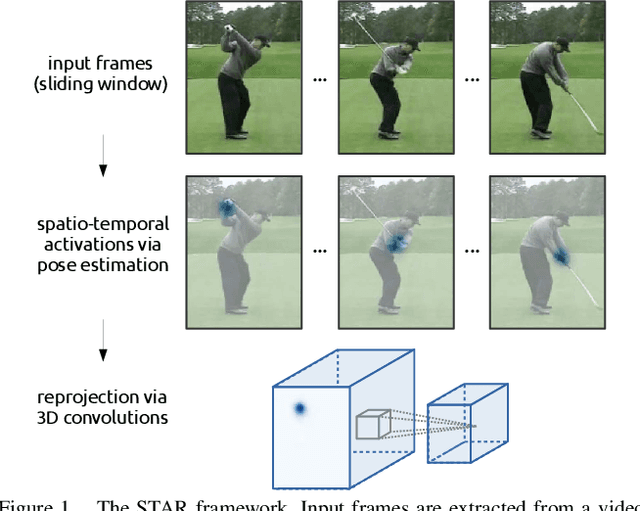
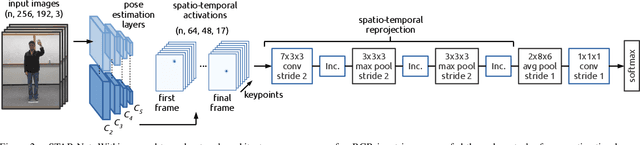


While depth cameras and inertial sensors have been frequently leveraged for human action recognition, these sensing modalities are impractical in many scenarios where cost or environmental constraints prohibit their use. As such, there has been recent interest on human action recognition using low-cost, readily-available RGB cameras via deep convolutional neural networks. However, many of the deep convolutional neural networks proposed for action recognition thus far have relied heavily on learning global appearance cues directly from imaging data, resulting in highly complex network architectures that are computationally expensive and difficult to train. Motivated to reduce network complexity and achieve higher performance, we introduce the concept of spatio-temporal activation reprojection (STAR). More specifically, we reproject the spatio-temporal activations generated by human pose estimation layers in space and time using a stack of 3D convolutions. Experimental results on UTD-MHAD and J-HMDB demonstrate that an end-to-end architecture based on the proposed STAR framework (which we nickname STAR-Net) is proficient in single-environment and small-scale applications. On UTD-MHAD, STAR-Net outperforms several methods using richer data modalities such as depth and inertial sensors.