 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked What-Where Auto-encoders
Paper and Code
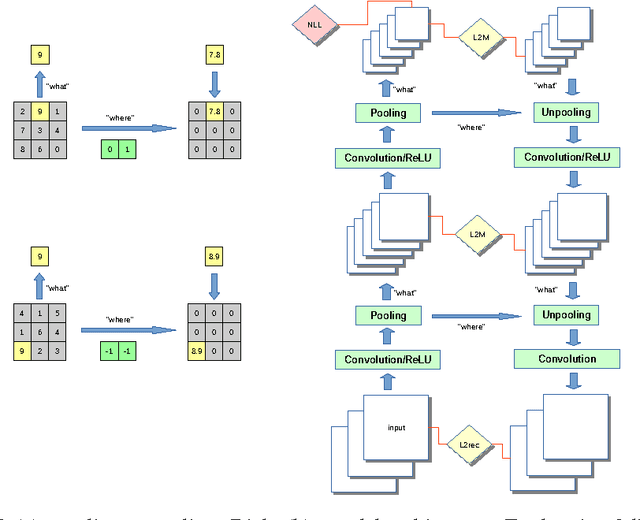



We present a novel architecture, the "stacked what-where auto-encoders" (SWWAE), which integrates discriminative and generative pathways and provides a unified approach to supervised, semi-supervised and unsupervised learning without relying on sampling during training. An instantiation of SWWAE uses a convolutional net (Convnet) (LeCun et al. (1998)) to encode the input, and employs a deconvolutional net (Deconvnet) (Zeiler et al. (2010)) to produce the reconstruction. The objective function includes reconstruction terms that induce the hidden states in the Deconvnet to be similar to those of the Convnet. Each pooling layer produces two sets of variables: the "what" which are fed to the next layer, and its complementary variable "where" that are fed to the corresponding layer in the generative decoder.