 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Temporal Attention: Improving First-person Action Recognition by Emphasizing Discriminative Clips
Paper and Code
Dec 02, 2021
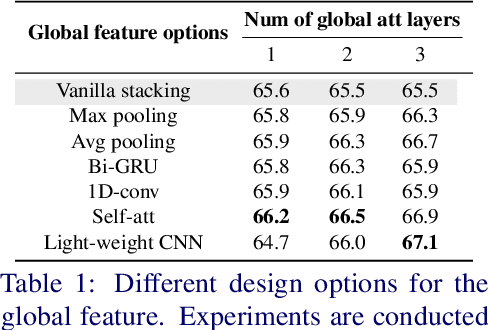
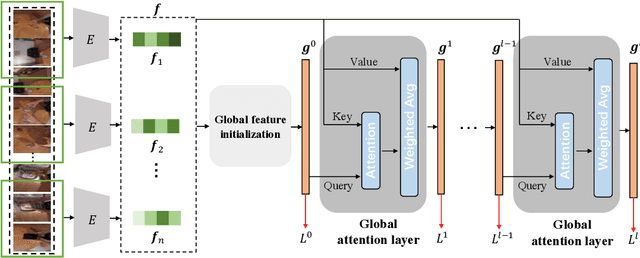
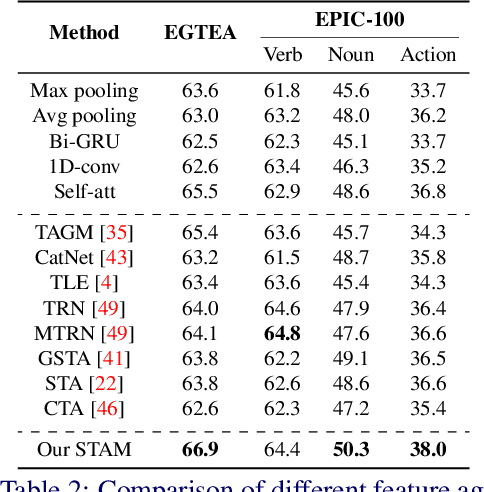
First-person action recognition is a challenging task in video understanding. Because of strong ego-motion and a limited field of view, many backgrounds or noisy frames in a first-person video can distract an action recognition model during its learning process. To encode more discriminative features, the model needs to have the ability to focus on the most relevant part of the video for action recognition. Previous works explored to address this problem by applying temporal attention but failed to consider the global context of the full video, which is critical for determining the relatively significant parts. In this work, we propose a simple yet effective Stacked Temporal Attention Module (STAM) to compute temporal attention based on the global knowledge across clips for emphasizing the most discriminative features. We achieve this by stacking multiple self-attention layers. Instead of naive stacking, which is experimentally proven to be ineffective, we carefully design the input to each self-attention layer so that both the local and global context of the video is considered during generating the temporal attention weights. Experiments demonstrate that our proposed STAM can be built on top of most existing backbones and boost the performance in various datasets.