 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable deep reinforcement learning method by predicting uncertainty in rewards as a subtask
Paper and Code
Jan 18, 2021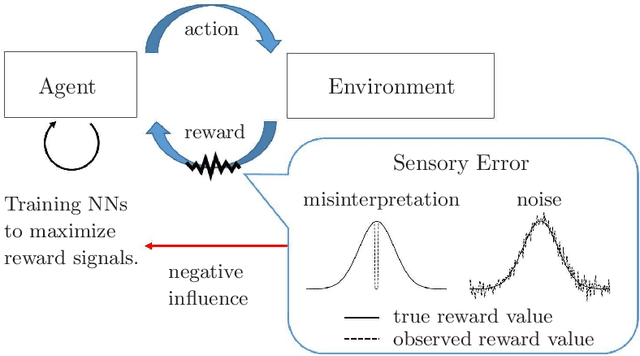
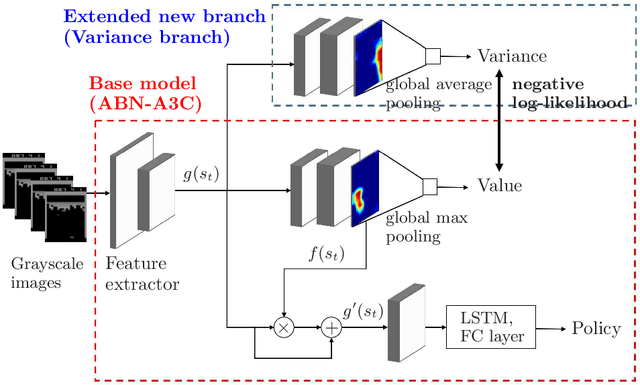
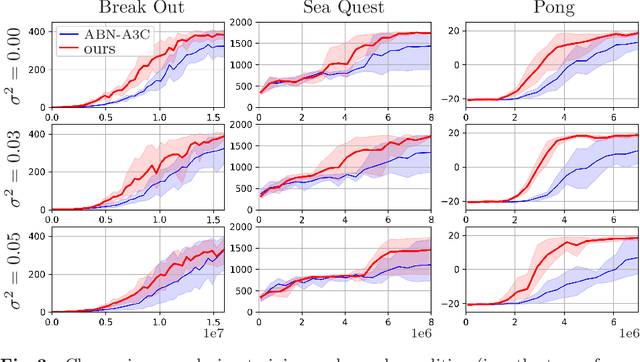
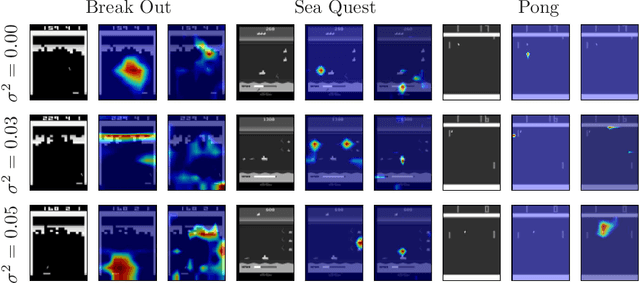
In recent years, a variety of tasks have been accomplished by deep reinforcement learning (DRL). However, when applying DRL to tasks in a real-world environment, designing an appropriate reward is difficult. Rewards obtained via actual hardware sensors may include noise, misinterpretation, or failed observations. The learning instability caused by these unstable signals is a problem that remains to be solved in DRL. In this work, we propose an approach that extends existing DRL models by adding a subtask to directly estimate the variance contained in the reward signal. The model then takes the feature map learned by the subtask in a critic network and sends it to the actor network. This enables stable learning that is robust to the effects of potential noise. The results of experiments in the Atari game domain with unstable reward signals show that our method stabilizes training convergence. We also discuss the extensibility of the model by visualizing feature maps. This approach has the potential to make DRL more practical for use in noisy, real-world scenarios.