 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability, Generalization and Privacy: Precise Analysis for Random and NTK Features
Paper and Code
May 20, 2023
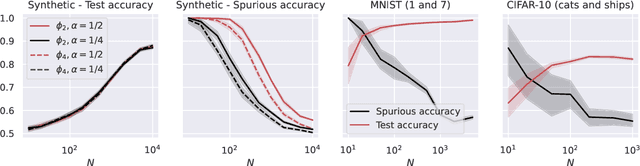
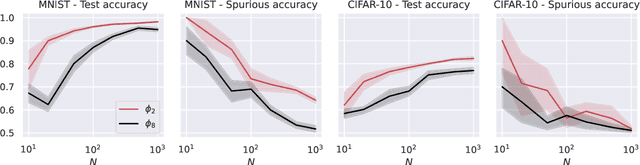
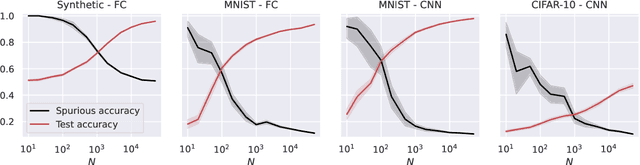
Deep learning models can be vulnerable to recovery attacks, raising privacy concerns to users, and widespread algorithms such as empirical risk minimization (ERM) often do not directly enforce safety guarantees. In this paper, we study the safety of ERM-trained models against a family of powerful black-box attacks. Our analysis quantifies this safety via two separate terms: (i) the model stability with respect to individual training samples, and (ii) the feature alignment between the attacker query and the original data. While the first term is well established in learning theory and it is connected to the generalization error in classical work, the second one is, to the best of our knowledge, novel. Our key technical result provides a precise characterization of the feature alignment for the two prototypical settings of random features (RF) and neural tangent kernel (NTK) regression. This proves that privacy strengthens with an increase in the generalization capability, unveiling also the role of the activation function. Numerical experiments show a behavior in agreement with our theory not only for the RF and NTK models, but also for deep neural networks trained on standard datasets (MNIST, CIFAR-10).